



In the upcoming weeks, I will share a collection of articles that will provide a comprehensive overview of Ethereum’s scalability potential. The goal is to establish a clear understanding of the challenges involved in creating a scalable cryptocurrency framework and to identify the minimal trade-offs and compromises needed to address those challenges. Initially, I plan to examine the core issues with Ethereum 1.0 as it exists today, along with other cryptocurrency platforms, and introduce limited solutions to specific issues that can significantly enhance efficiency – sometimes improving efficiency by a constant factor, and at other times making more fundamental improvements in complexity theory – but only applicable to very narrow use cases. As the series progresses, I will delve into more extensive generalizations of these mechanisms, ultimately culminating in an overarching generalization: applying the strategies I outline to enhance specific applications within Ethereum itself to guide us towards Ethereum 2.0.
At its core, scaling frameworks like Bitcoin and Ethereum presents a significant challenge; the consensus architectures depend heavily on each node verifying every transaction in a deep manner. While there are protocols for “light clients” working with Ethereum that store only a minimal part of the blockchain and utilize Merkle trees for secure access, the network still depends on a relatively substantial number of full nodes to maintain high security levels. Achieving transaction volumes comparable to Visa or SWIFT is achievable, but requires compromising decentralization, as only a limited number of full nodes would endure. To reach such transaction levels and even exceed them with micropayments, we must design a consensus framework that represents a fundamental enhancement over the model of “every node processing every transaction.” However, it turns out there is much we can accomplish without making such drastic changes.
Enhancements to Protocol
Image from https://bitcoin.org/en/developer-guide
The initial step towards enhancing space efficiency involves some modifications to the protocol—modifications that have been an integral part of Ethereum since its inception. The first alteration is the transition from a UTXO-based architecture to an account-based approach. Bitcoin’s blockchain operates on the principle of “unspent transaction outputs,” where each transaction incorporates one or multiple inputs and outputs, with the condition that each input refers to a valid and unspent previous output and the total of outputs does not exceed the total of inputs. This necessitates larger transaction sizes, often with multiple signatures from the same user, requiring around 50 bytes to be stored in the database for each transaction received by a node. This becomes particularly cumbersome when managing an account that’s receiving numerous small payments; for example, in the case of ethereum.org, clearing our exodus address will involve hundreds of transactions.
In contrast, Ripple and Ethereum employ a more standardized method of transactions that involve depositing to and withdrawing from accounts, ensuring that each account occupies only around 100 bytes on the blockchain, irrespective of usage level. A second modification common to both Ripple and Ethereum is storing the entire blockchain state in a Patricia tree in each block. This Patricia tree structure is specifically designed to maximize deduplication, which means that if you’re storing many almost-identical Patricia trees for successive blocks, you only need to save the majority of the data once. This enables nodes to more effortlessly “start from the middle” and securely download the current state without having to process the entire history.
These strategies, of course, are offset by the reality that Ethereum accommodates a broader spectrum of applications and, as a result, a much more dynamic usage pattern. Ultimately, such optimizations have their limits. Thus, to advance further, we must look beyond minor adjustments to the protocol itself and explore solutions that build upon it.
Batch Processing
In Bitcoin, a transaction that uses ten previously unspent outputs necessitates ten signatures. In Ethereum, any one transaction requires one signature (although certain constructs like multisig accounts may require multiple transactions for a withdrawal). However, we can take this a step further by establishing a system that allows ten withdrawals to require just one transaction and one signature. This represents another constant-factor enhancement, albeit a potentially quite powerful one: batch processing.


The concept behind batching is straightforward: consolidate multiple sends into a single transaction within the data fields and then have a forwarding contract distribute the payment. Below is a simple implementation of such a contract:
i = 0 while i msg.datasize: send(msg.data[i], msg.data[i+1]) i += 2
We can further enhance it to facilitate the forwarding of messages by utilizing certain low-level EVM commands in serpent to perform byte-by-byte packing:
init: contract.storage[0] = msg.sender code: if msg.sender != contract.storage[0]: stop i = 0 while i ~calldatasize(): to = ~calldataload(i) value = ~calldataload(i+20) / 256^12 datasize = ~calldataload(i+32) / 256^30 data = alloc(datasize) ~calldatacopy(data, i+34, datasize) ~call(tx.gas - 25, to, value, data, datasize, 0, 0) i += 34 + datasize
Rather than using your typical account to interact with contracts, the concept is that you would secure your assets and manage your relationships with contracts through this account, enabling you to perform numerous operations all at once within a single transaction.
Be aware that this approach has its boundaries. While it can significantly increase the workload achievable with a single signature, the data required for registering the recipient, value, and message data, along with the computational resources needed to process transactions, remains constant. The significance of signatures should not be overlooked; signature verification is likely the most resource-intensive aspect of blockchain validation, yet the efficiency improvement from using such a mechanism is still confined to maybe a factor of four for straightforward transactions and even lower for those requiring extensive computation.
Micropayment Channels
A widely aspired application of cryptocurrency is the notion of micropayments – establishing marketplaces for very small units of computational or physical resources, paying for utilities like electricity, internet bandwidth, file storage, road usage, or any other micro-meterable item, cent by cent. Existing cryptocurrencies are indeed beneficial for much smaller transactions than previously possible; Paypal imposes a fixed fee of $0.30 per transaction, while Bitcoin currently charges about $0.05, making it reasonable to undertake payments as low as 50 cents. However, if we aim to pay $0.01 incrementally, we require a considerably improved system. There is no straightforward universal solution to implement; if there were, that would constitute Ethereum 2.0. Instead, there exists a combination of various methods, each tailored for specific use cases. A prevalent application is micropayment channels: scenarios where one party compensates the other over time for a metered service (e.g., a file download), with the transaction needing to be processed only at the conclusion. Bitcoin facilitates micropayment channels; Ethereum does too, and arguably in a somewhat more elegant manner.
The channel operates approximately as follows: the sender initiates a transaction to set up a channel, indicating a recipient, and the contract establishes a channel with an initial value of zero and assigns an ID for the channel.To enhance the payment on the channel, the sender authenticates a data packet of the structure [id, value], with value representing the updated value to convey. Once the channel activity is completed and the receiver desires to cash out, they simply need to retrieve the signed [id, value, v, r, s] packet (the v,r,s trio being an elliptic curve signature) and submit it to the blockchain as transaction data, allowing the contract to validate the signature. If the signature proves to be legitimate, the contract waits for 1000 blocks for a packet with a greater value for the transaction ID to be submitted, after which it can be prompted again to dispatch the funds. It’s important to note that if the sender attempts to deceive by presenting an earlier packet with a lesser value, the receiver has the 1000 block period to submit the higher-valued packet. Below is the code for the validator:
# Create channel: [0, to] if msg.data[0] == 0: new_id = contract.storage[-1] # save [from, to, value, maxvalue, timeout] in contract storage contract.storage[new_id] = msg.sender contract.storage[new_id + 1] = msg.data[1] contract.storage[new_id + 2] = 0 contract.storage[new_id + 3] = msg.value contract.storage[new_id + 4] = 2^254 # increment next id contract.storage[-1] = new_id + 10 # return id of this channel return(new_id)elif msg.data[0] == 2:
id = msg.data[1] % 2^160 # Check if timeout has elapsed
if block.number >= contract.storage[id + 3]: # Dispense funds
send(contract.storage[id + 1], contract.storage[id + 2]) # Refund dispatch
send(contract.storage[id], contract.storage[id + 3] - contract.storage[id + 2]) # Empty storage
contract.storage[id] = 0
contract.storage[id + 1] = 0
contract.storage[id + 2] = 0
contract.storage[id + 3] = 0
contract.storage[id + 4] = 0
And there we have it. All that remains now is an adequate off-chain user interface for managing the consumer-merchant aspect of the transaction.
Probabilistic Micropayments
However, micropayment channels are not a cure-all. What happens if you only need to pay $0.007 to download a 32 MB file from someone, making even the total transaction cost not warrant the single final transaction fee? In this case, we implement something a bit more ingenious: probabilistic micropayments. Fundamentally, a probabilistic micropayment takes place when a sender executes an action that provably holds a defined probability of facilitating a specific payment in the future; in this instance, we might execute a 0.7% chance of sending $1. Over the long haul, both expenses and receipts will align closely with those in the non-probabilistic framework, but with the advantage of reducing transaction costs by 99%.
So, how do we“`html
How do probabilistic micropayments operate? The typical method involves the payment being a signed data packet structured as [nonce, timeout, to, value, prob], where nonce represents a random integer, timeout signifies a block number set in the near future, to indicates the payee, value is the ether amount intended for transfer and prob represents the chance of transmission multiplied by 232. After the block number exceeds timeout, permission is granted for the data packet to be added to the blockchain and cashed out only if a random number generator, initialized with the nonce, produces a value where mod 232 is lesser than prob.
Given a random number generator, the code example for the fundamental receiving function is:
# Cash out: [0, nonce, timeout, to, value, prob, v, r, s] if msg.data[0] == 0: # Helper contracts (addresses will not function on testnet or livenet) ecrecover = 0x46a8d0b21b1336d83b06829f568d7450df36883f random = 0xb7d0a063fafca596de6af7b5062926c0f793c7db # Variables timeout = msg.data[2] to = msg.data[3] value = msg.data[4] prob = msg.data[5] # Is it the right moment to cash out? if block.number >= timeout: # Generating randomness if call(random, [0, nonce, timeout], 3) % 2^32 msg.data[5]: # Identify the sender h = sha3(slice(msg.data, 1), 5) sender = call(ecrecover, [h, msg.data[ ```7], msg.data[8]], 4) # Withdraw if contract.storage[sender] >= value: contract.storage[sender] -= value send(to, value)
There exist two “challenging aspects” in the execution of this method. One concerns double-spending threats, while the other revolves around devising the random number generator. To counter double-spending threats, the approach is straightforward: impose an exceptionally high security deposit in the contract alongside the ether balance that the account can send. Should the sendable balance decrease below zero, the entire deposit is forfeited.
The latter aspect is, of course, how to initially create a random number generator. Typically, the primary source of randomness utilized within Ethereum is block hashes; since micropayments represent low-value transactions, and due to the unique nonce employed in each transaction ensuring that a block hash is highly improbable to favor any particular user in any specific manner, block hashes are expected to be adequate for this requirement – however, it is essential to ensure that we acquire a specific block hash rather than merely the block hash at the moment a request is initiated (using the block hash at the time a request is sent is also effective, but not as efficient, as the sender and recipient are likely to attempt to hinder each other’s efforts to transmit claim transactions during blocks that are disadvantageous to them). One potential solution is to have a centralized contract keep a record of the block hash for each block, incentivizing miners to notify it for every block; the contract could levy a micropayment for its API to cover the service costs. For optimal efficiency, it can be constrained to offer a reward once in every ten blocks. In cases where the contract misses a block, the following block hash is employed.
The code for the once-every-ten-blocks version is:
# If we receive a ping for the first time in a new epoch, establish the prevhash if !contract.storage[block.number / 10]: send(msg.sender, 10^17) contract.storage[block.number / 10] = block.prevhash # If not, provide the block hash: [0, block number] if msg.data == 0 and msg.value > 10^16: return(contract.storage[msg.data[1] / 10])
To transform this into an appropriate implementation of the random contract, we merely execute:
# When we receive a ping for the first time in a new epoch, initialize the prevhash if !contract.storage[block.number / 10]: send(msg.sender, 10^17) contract.storage[block.number / 10] = block.prevhash # Else, generate the hash from the block hash combined with a nonce: [0, block number, nonce] if msg.data == 0 and msg.value > 10^16: return(sha3([contract.storage[msg.data[1] / 10], msg.data[2]], 2))
It is essential to understand that for something like this to perform effectively, one “higher-level” infrastructure component that needs to exist is a form of incentivized pinging. This task can be accomplished collaboratively with a pub/sub contract: a contract can be established to which other contracts can subscribe by paying a minimal fee, and when the contract is pinged for the first time within N blocks, it offers a singular reward and immediately pings all subscribed contracts. This method is still susceptible to some exploitation by miners, but the low-value aspect of micropayments and the independence of each payment should significantly mitigate the issue.
Off-chain oracles
In keeping with the concept of signature batching, a strategy that advances even further is to execute the entire computation off the blockchain. To achieve this securely, we employ a clever economic workaround: the code remains on the blockchain, where it is recorded, but by default, the computation is executed by oracles which run the code off-chain in a private EVM and provide the answer, also backed by a security deposit. Upon supplying the answer, it requires 100 blocks for the answer to be committed; if everything proceeds well, the answer can be confirmed on the blockchain after 100 blocks, enabling the oracle to retrieve its deposit along with a minor bonus. However, during that 100-block duration, any node can verify the computation independently, and if they observe that the oracle is incorrect, they can finance an auditing transaction – essentially running the code on the blockchain to compare the outcome. Should the results differ, the auditor receives 90% of the block reward, while 10% is obliterated.
This essentially offers near-equivalent guarantees to each node executing the code, except that in reality, only a limited number of nodes do so. Notably, if a financial contract is in place, the participants in that contract have a substantial incentive to conduct the audit, as they stand to be adversely affected by an invalid block. While this scheme is elegant, it does present some inconvenience; users must wait 100 blocks before they can utilize the results of their code.
To address this limitation, the protocol can be further expanded. The concept now is to establish an entire “shadow chain,” where computations occur off-chain but state transitions are subsequently committed back to the main chain after 100 blocks. Oracles can append new blocks to the “tail” of the chain, with each block containing a list of transactions alongside a [[k1, v1], [k2, v2] … ] array of state transitions triggered by those transactions. If a block remains unchallenged for 100 blocks, the state transitions will automatically be applied to the main chain. Conversely, if the block is successfully contested before its commitment, that block along with all its descendants will be rolled back, and both the block and its descendants will forfeit their deposits, with part allocated to the auditor and part lost (notably, this provides additional motivation for auditing, as now, the creator of any child of a shadow block would prefer to audit the block to avoid being implicated in possible fraudulent activity). The code responsible for this is significantly more complex than the previous examples; a complete yet untested version can be accessed here.
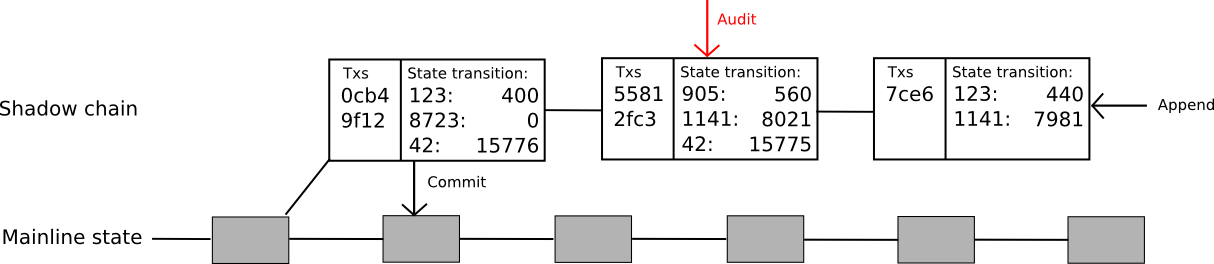

It is important to highlight that this protocol remains constrained: it addresses the signature verification issue and solves the state transition computation dilemma, yet it does not resolve the data problem. Each transaction in this framework still must be downloaded by every node. How can we improve even further? As it turns out, there is potential for enhancement; however, advancing beyond this requires addressing a much broader issue: the data challenge.