



A significant and contentious subject in the realm of personal wallet security is the idea of “brainwallets” – securing assets utilizing a private key created from a password retained solely in one’s memory. Theoretically, brainwallets could offer an almost idyllic assurance of safety for long-term investments: as long as they remain dormant, they are impervious to tangible theft or any form of hacking, and there is no way to even demonstrate that you continue to recall the wallet; they are as secure as your very own cognitive ability. Nevertheless, many have contested the use of brainwallets, arguing that the human memory is delicate and not optimally designed for generating, or recalling, long and complex cryptographic secrets, making them too perilous for practical application. Which perspective is accurate? Is our recollection adequately strong to safeguard our private keys, too feeble, or is there perhaps a third and more intriguing scenario at play: that it all hinges on how the brainwallets are crafted?
Entropy
If the task at hand is to devise a brainwallet that is both memorable and secure, then there are two factors we must consider: the volume of information we need to retain, and the duration it takes for an intruder to decipher the password. Interestingly, the challenge in the problem arises from the fact that the two factors are highly interconnected; indeed, without a few particular kinds of special techniques and assuming an attacker utilizing an optimal algorithm, they are essentially equivalent (or rather, one is proportional to the exponential of the other). However, to begin with, we can address the two aspects of the issue independently.
A common metric that computer scientists, cryptographers, and mathematicians employ to quantify “how much information” a piece of data embodies is “entropy”. Loosely defined, entropy is the logarithm of the count of potential messages that share the same “form” as a specific message. For instance, consider the number 57035. 57035 appears to belong to the category of five-digit numbers, of which there are 100000. Therefore, the number encompasses approximately 16.6 bits of entropy, as 216.6 ~= 100000. The number 61724671282457125412459172541251277 is 35 digits in length, and log(1035) ~= 116.3, granting it 116.3 bits of entropy. A random sequence of ones and zeroes n bits in length will contain exactly n bits of entropy. Thus, longer sequences possess more entropy, and sequences with a broader range of symbols available have increased entropy.
Conversely, the number 11111111111111111111111111234567890 contains significantly less than 116.3 bits of entropy; although it comprises 35 digits, the number does not fit the category of 35-digit numbers, rather it falls into the category of 35-digit numbers with a very high degree of structure; a complete list of numbers exhibiting at least that level of structure might consist of merely a few billion entries, providing it possibly only 30 bits of entropy.
Information theory offers several more formal definitions attempting to encapsulate this intuitive idea. A particularly well-known one is the concept of Kolmogorov complexity; the Kolmogorov complexity of a string is essentially the length of the briefest computer program that can produce that value. In Python, the aforementioned string can also be represented as ‘1’*26+’234567890′ – an 18-character string, while 61724671282457125412459172541251277 requires 37 characters (the actual digits plus quotes). This provides us with a more formal comprehension of the notion of “category of strings with significant structure” – those strings are simply the collection of strings that necessitate a minimal amount of data for representation. It should be noted that there are other compression methods we could utilize; for example, unbalanced strings like 1112111111112211111111111111111112111 can be reduced by at least half by creating specific symbols that denote multiple 1s sequentially. Huffman coding serves as an example of an information-theoretically optimal method for executing such transformations.
Lastly, it’s important to acknowledge that entropy is context-dependent. The string “the quick brown fox jumped over the lazy dog” might possess over 100 bytes of entropy when represented as a simple Huffman-coded sequence of characters, yet due to our understanding of English, and the fact that numerous articles and papers in information theory have utilized that very phrase, the actual entropy may be around 25 bytes – I might designate it as “fox dog phrase” and using Google you can ascertain what it refers to.
So what is the significance of entropy? Essentially, entropy measures the quantity of information you need to memorize. The greater the entropy, the more challenging it is to commit to memory. Therefore, at first glance, it appears that you should seek passwords that are as low-entropy as possible while simultaneously being difficult to decipher. However, as we will explore below, this line of thinking is rather perilous.
Strength
Now, let us move to the next aspect, password security against intruders. The security of a password is optimally assessed by the anticipated number of computational steps required for an intruder to guess your password. For randomly generated passwords, the most straightforward algorithm to implement is brute force: attempt all conceivable one-character passwords, then all two-character passwords, and so on. With an alphabet of n characters and a password of length k, such an algorithm would resolve the password in approximately nk time. Thus, the greater the number of characters you utilize, the more advantageous, and the lengthier your password, the more beneficial it is.
There exists an approach that seeks to elegantly merge these two strategies without being overly cumbersome to memorize: Steve Gibson’s haystack passwords. As Steve Gibson elucidates:
Which of the following two passwords is stronger, more secure, and harder to decipher?
You likely realize this is a trick inquiry, but the answer is: Despite the first password being FAR more user-friendly and memorable, it is also the more robust of the two! In fact, given that it is one character longer and incorporates uppercase, lowercase, a digit, and special characters, that first password would require an intruder approximately 95 times more duration to discover through search compared to the second password that is impossible to remember or type!
Steve further notes: “Almost universally, individuals have always believed or been informed that passwords derive their strength from possessing “high entropy”. However, as we now observe, when the only feasible attack is guessing, that time-honored conventional wisdom . . . is . . . not . . . accurate!” Nevertheless, as alluringas such a gap exists, regrettably in this aspect he is completely incorrect. This is due to its dependence on particular traits of attacks that are frequently employed, and should it gain extensive usage, adversaries could swiftly devise targeted attacks against it. In fact, there exists a universal attack that, with an adequate number of exposed password examples, can automatically adjust itself to manage nearly anything: Markov chain samplers.
The operation of the algorithm proceeds as follows. Assume that your alphabet comprises solely the symbols 0 and 1, and from sampling, you determine that a 0 is succeeded by a 1 65% of the time and a 0 35% of the time, while a 1 is succeeded by a 0 20% of the time and a 1 80% of the time. To randomly sample the dataset, we construct a finite state machine embodying these probabilities and simply execute it in a loop repeatedly.

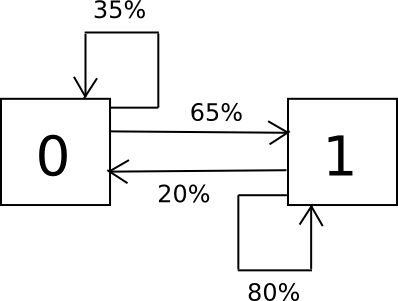
Here is the Python code:
import random i = 0 while 1: if i == 0: i = 0 if random.randrange(100) 35 else 1 elif i == 1: i = 0 if random.randrange(100) 20 else 1 print i
We take the results, partition them into segments, and there we possess a method of producing passwords that mimic the patterns of passwords commonly used by individuals. We can extend this beyond two characters to encompass a complete alphabet, and we might even allow the state to monitor not just the last character but the preceding two, three, or more. Therefore, if many individuals begin creating passwords such as “D0g…………………”, after observing several thousand instances, the Markov chain will “understand” that users frequently generate lengthy strings of periods, and when it outputs a period, it may frequently find itself temporarily trapped in a cycle of producing more periods for a few iterations – probabilistically simulating human behavior.
One element that was omitted is the method for terminating the loop; as it stands, the code merely produces an endless sequence of zeroes and ones. We could incorporate a pseudo-symbol into our alphabet indicating the conclusion of a string and integrate the observed frequency of that symbol into our Markov chain probabilities, but this isn’t ideal for this scenario – since shorter passwords are significantly more prevalent than longer ones, it would typically generate exceedingly brief passwords, thereby repeating the short passwords millions of times before attempting most of the longer ones. Therefore, we might want to artificially limit it to a certain length and gradually increase that limit over time, although more sophisticated approaches exist, such as running a concurrent Markov chain in reverse. This broad category of method is typically referred to as a “language model” – a probability distribution over sequences of characters or words that can be as simple and rough or complex and detailed as necessary, and which can then be sampled.
The primary reason why the Gibson approach fails, and why no other strategy of that nature could possibly succeed, is that within the definitions of entropy and strength, there exists a fascinating equivalence: entropy represents the logarithm of the number of options, whereas strength denotes the quantity of options – in essence, memorability and vulnerability to attack are consistently equivalent! This holds true regardless of whether you are randomly selecting characters from an alphabet, words from a lexicon, characters from a biased alphabet (for example, “1” 80% of the time and “0” 20% of the time, or sequences that follow a specific pattern). Consequently, it appears that the pursuit of a secure yet memorable password is a futile endeavor…
Easing Memory, Fortifying Attacks
… or perhaps not. Even though the fundamentalThe notion that entropy which must be internalized and the effort an attacker must expend are precisely the same is both mathematically and computationally valid. However, the complication arises in the practical world where several complexities exist that we can leverage to adjust the equation in our favor.
The first crucial observation is that human memory does not function like a computer’s data storage; the degree to which one can accurately recall information frequently relies on how it is memorized and in what format it is stored. For instance, we tend to remember kilobytes of data effortlessly when it comes to human faces, whereas something as seemingly similar as dog faces poses a significant challenge. Text-based information is even more challenging to remember – although memorizing text both visually and orally can alleviate some difficulty.
Some individuals have attempted to capitalize on this insight by creating random brainwallets and encoding them as sequences of words; for example, one might encounter something like:
witch collapse practice feed shame open despair creek road again ice least
A well-known XKCD comic exemplifies this principle, advising that users generate passwords by creating four random words rather than attempting to be clever with symbol manipulation. This method appears refined, and by potentially leveraging our differing capacities to remember random symbols versus language, it could indeed be effective. Unfortunately, there lies a complication: it does not work.
To quote a recent investigation by Richard Shay and colleagues from Carnegie Mellon:
In a study involving 1,476 online participants, we examined the usability of system-assigned 3- and 4-word passphrases in relation to system-assigned passwords composed of 5 to 6 random characters and 8-character pronounceable passwords. Contrary to our expectations, system-assigned passphrases performed comparably to system-assigned passwords of similar entropy across the usability measures we assessed. Passphrases and passwords were forgotten at comparable rates, resulted in similar user difficulties and frustrations, and were both noted down by a majority of participants. However, participants took substantially longer to input passphrases, and they seem to necessitate error correction to counteract input errors. Reducing the dictionary size from which words were selected, decreasing the word count in a passphrase, or permitting users to modify the word order did not enhance the usability of passphrases.
Nevertheless, the paper concludes on a hopeful note. It highlights that there are methods to create passwords with greater entropy, and therefore superior security, while still being equally easy to memorize; randomly generated yet pronounceable strings such as “zelactudet” (presumably generated through some character-based language model sampling) appear to offer a moderate improvement over both word lists and randomly created character strings. This likely occurs because pronounceable passwords can be remembered both as sounds and sequences of letters, enhancing redundancy. Thus, we have at least one tactic for boosting memorability without compromising strength.
Another approach is to tackle the issue from the converse perspective: make it more challenging to break the password without increasing its entropy. We cannot enhance the difficulty of cracking the password by increasing the number of combinations, as that would raise entropy, but we can employ what is referred to as a hard key derivation function. For instance, suppose our memorized brainwallet is b; instead of deriving the private key using sha256(b) or sha3(b), we could compute it as F(b, 1000) where F is defined as follows:
def F(b, rounds): x = b i = 0 while i rounds: x = sha3(x + b) i += 1 return x
Fundamentally, we continuously input b into the hash function repeatedly, and it is only after 1000 iterations that we derive the output.


Reintroducing the original input into each iteration isn’t strictly required, but cryptographers advocate for it to mitigate the impact of attacks using pre-calculated rainbow tables. Now, verifying each individual password takes a thousand times longer. You, as the authentic user, won’t perceive the difference – it’s 20 milliseconds rather than 20 microseconds – yet against adversaries you gain ten bits of entropy at no extra memorization cost. If you increase to 30000 iterations, you receive fifteen bits of entropy, but this would result in password computation taking nearly a second; 20 bits would require 20 seconds, and after about 23 it becomes impractical.
Currently, there exists an ingenious method we can employ to go even further: outsourceable ultra-expensive KDFs. The concept is to devise a function that is extremely resource-intensive to compute (for instance, 240 computational steps), but can be executed in some manner without granting the entity executing the function access to the output. The cleanest, albeit most cryptographically intricate, method of achieving this is to create a function that can in some way be “blinded” such that unblind(F(blind(x))) = F(x), where blinding and unblinding necessitates a one-time randomly generated secret. You then compute blind(password), and send the task to a third party, optimally with an ASIC, and subsequently unblind the response upon receipt.

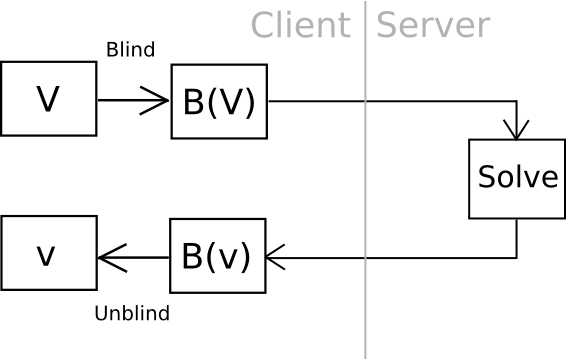
One illustration of this is utilizing elliptic curve cryptography: generate a feeble curve where the values are merely 80 bits long instead of 256, and establish the hard problem as a discrete logarithm computation. This means we calculate a value x by hashing a value, find the corresponding y on the curve, and then “blind” the (x,y) point by adding another randomly generated point, N (whose corresponding private key we know to be n), and then send the output to a server for cracking. Once the server derives the private key corresponding to N + (x,y), we subtract n, resulting in the private key associated with (x,y) – our desired outcome. The server does not learn any details about this value, or even what (x,y) is – theoretically, it could be anything with the proper blinding factor N. Additionally, it’s important to note that the user can quickly verify the work – simply convert the private key received back into a point, and confirm that the point is indeed (x,y).

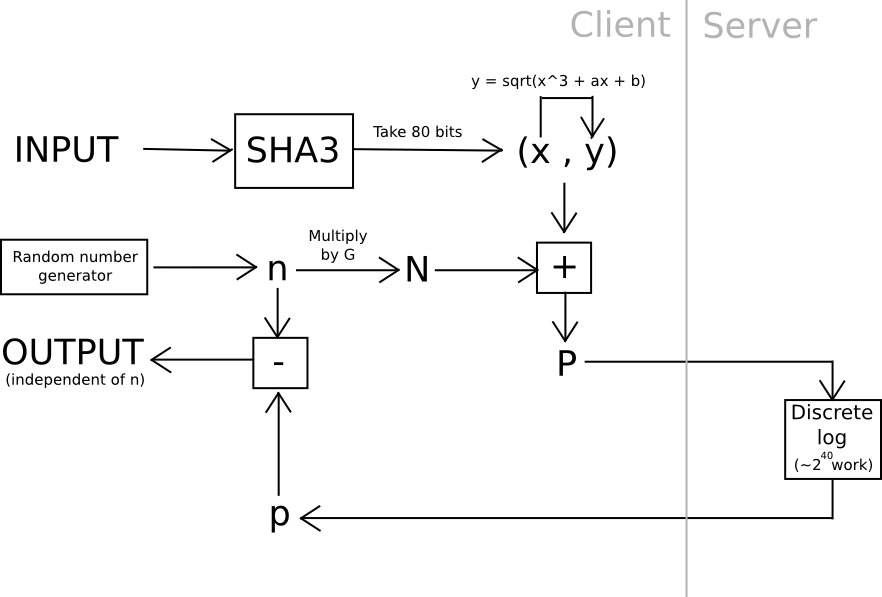
Another strategy leans less on the algebraic characteristics of nonstandard and intentionally weak elliptic curves: utilize hashes to generate 20 seeds from a password, apply a significantly tough proof of work problem to each one (for example, calculating f(h) = n where n is such that sha3(n+h) ), and merge the results using a moderately challenging KDF at the conclusion. Unless all 20 servers conspire (which can be prevented if the user routes through Tor, since it would be impossible even for an attacker observing or controlling 100% of the network to determine which requests originate from the same user), the protocol remains secure.

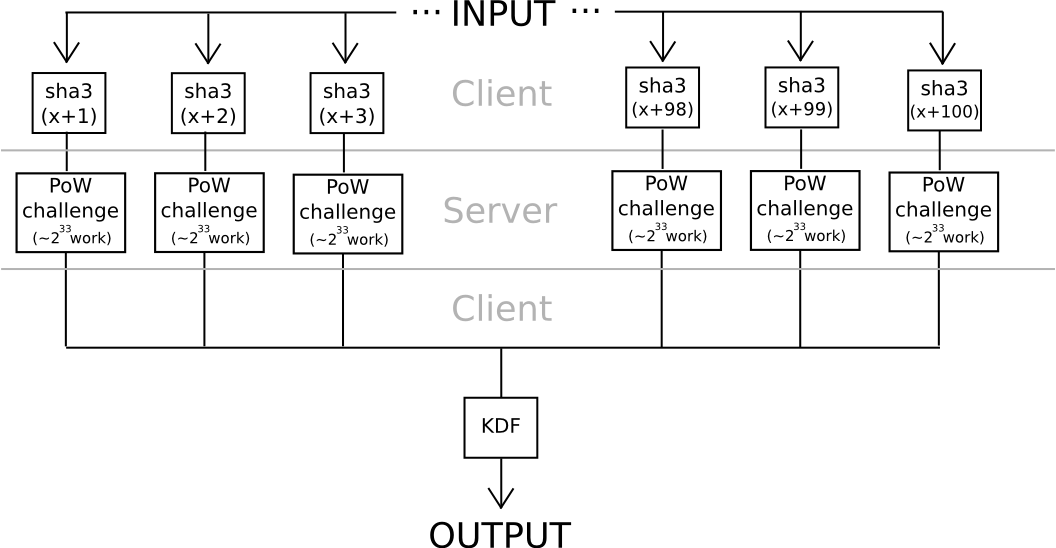
The intriguing aspect of both of these protocols is that they are relatively simple to convert into a “useful proof of work” consensus mechanism for a blockchain; anyone could present work for the chain to process, the chain would carry out the computations, and both elliptic curve discrete logs and hash-based proofs of work are quite straightforward to validate. The elegant part of the model is that it utilizes both users’ expenditures in performing the work function, as well as the attackers’ significantly greater costs. If the blockchain subsidizes the proof of work, it would become optimal for attackers to also endeavor to breach users’ passwords by submitting work to the blockchain; in which case, attackers would inadvertently contribute to the security of consensus in the process. But then, realistically at this level of security, where 240 work is required to compute a single password, brainwallets and other passwords would be so fortified that no one would even find it worthwhile to attack them.
Entropy Differentials
Now, we arrive at our concluding, and most fascinating, memorization technique. From our previous discussions, we recognize that entropy, the volume of information within a message, and the complexity of an attack are essentially aligned – unless you intentionally slow down the process via costly KDFs. However, there is another factor regarding entropy that was mentioned briefly, and is indeed vital: perceived entropy is context-dependent. The name “Mahmoud Ahmadjinejad” may possess around ten to fifteen bits of entropy to us, but to someone residing in Iran during his presidency, it might consist of only four bits – in their hierarchy of the most significant individuals in their lives, he is likely in the top sixteen. Your parents or partner are entirely unfamiliar to me, and so for me, their names might hold about twenty bits of entropy, but to you they may only carry two or three bits.
What causes this phenomenon? Formally, the optimal way to conceptualize it is that for each individual, their past experiences form a sort of compression algorithm, and under various compression algorithms, or diverse programming languages, the same string can have varying Kolmogorov complexity. In Python, ‘111111111111111111’ can simply be ‘1’*18, yet in Javascript it is Array(19).join(“1”). In a theoretical version of Python where the variable x is set to ‘111111111111111111’, it can merely be x. The last example, although seemingly forced, actually best encapsulates much of the real world; the human mind is a system with numerous variables predefined by our prior experiences.
This rather straightforwardinsight paves the way for a particularly refined approach to password memorability: aim to develop a password where the “entropy differential”, the gap between your perception of entropy and that of others, is maximized. A straightforward technique is to add your own username at the beginning of the password. If my password were “yui&(4_”, I could modify it to “vbuterin:yui&(4_” instead. My username might offer around ten to fifteen bits of entropy to the outside world, but to me, it’s nearly just a single bit. This fundamentally explains why usernames are utilized as a protective element alongside passwords, even in situations where the notion of users having “names” is not strictly requisite.
Now, we can delve a bit deeper. One frequent piece of guidance that is now widely and universally criticized as ineffective is to choose a password by selecting a phrase from a book or song. The appealing aspect of this suggestion is that it seemingly skillfully takes advantage of differentials: the phrase might incorporate over 100 bits of entropy, while you merely need to recall the book as well as the page and line number. The issue is that, of course, everyone else has access to those books too, and they can easily conduct a brute force attack across all books, songs, and films using that data.
Nonetheless, the advice holds value; in fact, when applied as merely part of your password, a quote from a book, song, or movie serves as an excellent component. Why? Quite simple: it establishes a differential. Your beloved line from your favorite song possesses only a few bits of entropy for you, yet it isn’t a favorite song for everyone else, making it potentially hold ten to twenty bits of entropy in the eyes of the world. The ideal tactic is, therefore, to select a book or song that you genuinely enjoy, yet which is also maximally obscure – reducing your entropy while increasing that of others. Then, naturally, prepend your username and append some random characters (possibly even a random pronounceable “word” like “zelactudet”), and employ a robust KDF.
Conclusion
What level of entropy do you require for security? Currently, password-cracking devices can execute about 236 attempts every second, while Bitcoin miners are capable of achieving approximately 240 hashes per second (equivalent to 1 terahash). The collective power of the Bitcoin network amounts to 250 petahashes, or roughly 257 hashes within a second. Cryptographers typically consider 280 as a satisfactory minimum level of security. To yield 80 bits of entropy, you will need either approximately 17 random letters from the alphabet, or 12 random letters, numbers, and symbols. However, we can reduce the requirement significantly: fifteen bits for a username, fifteen bits for an effective KDF, perhaps ten bits for an abbreviation from a passage from a somewhat obscure song or book that you enjoy, and then an additional 40 bits of plain simple randomness. If you’re not utilizing a robust KDF, then you can incorporate other elements.
It has become increasingly common among security professionals to dismiss passwords as being fundamentally insecure, advocating for the complete replacement of password schemes. A prevalent argument is that due to Moore’s law, attackers’ capabilities increase by one bit of entropy every two years, necessitating continual memorization of more to maintain security. Yet, this assertion is not entirely accurate. When employing a strong KDF, Moore’s law enables you to offset bits from the attackers’ power just as swiftly as the attacker gains strength, and the fact that methods like those mentioned above, excluding KDFs (the moderate type, not the outsourceable variant), have yet to be fully explored suggests there is still substantial progress to be made. Overall, passwords remain as secure as they have ever been and serve as a valuable component of a robust security policy — just not the sole component. Moderate strategies that incorporate a blend of hardware wallets, trusted third parties, and brain wallets might ultimately prevail.