



One of the significant matters that has surfaced during the Olympic stress-net launch is the substantial quantity of data that users must retain; in just slightly over three months of operation, especially during the final month, the data volume within each Ethereum client’s blockchain directory has surged to an astonishing 10-40 gigabytes, varying based on the client utilized and whether compression is activated. Even though it is crucial to highlight that this represents a stress test environment where participants are encouraged to flood the blockchain with transactions solely paying the complimentary test-ether as a transaction fee, and the transaction throughput rates are thus considerably higher than Bitcoin, it remains a valid concern for users, many of whom do not possess hundreds of gigabytes to allocate for retaining other individuals’ transaction records.
To begin with, let’s delve into why the existing Ethereum client database is so extensive. Ethereum, in contrast to Bitcoin, possesses the feature that each block includes something known as the “state root”: the root hash of a distinct type of Merkle tree that keeps the complete state of the system: all account balances, contract storage, contract code, and account nonces are contained within it.
The rationale for this is straightforward: it enables a node, armed only with the most recent block, coupled with some assurance that this block indeed represents the latest one, to “synchronize” with the blockchain remarkably quickly without having to process any historical transactions. This is accomplished by merely downloading the remainder of the tree from nodes present in the network (the proposed HashLookup wire protocol message will aid in this), validating that the tree is accurate by confirming that all the hashes align, and then proceeding from there. In a fully decentralized environment, this will likely be executed using an enhanced version of Bitcoin’s headers-first-verification method, which would approximately unfold as follows:
- Acquire as many block headers as the client can obtain.
- Identify the header that is at the end of the longest chain. Beginning from that header, trace back 100 blocks for safety, and label the block at that position P100(H) (“the hundredth-generation grandparent of the head”)
- Download the state tree from the state root of P100(H), utilizing the HashLookup opcode (note that after the initial one or two iterations, this can be parallelized across as many peers as necessary). Confirm that all components of the tree align.
- Continue as normal from there.
For lightweight clients, the state root is even more beneficial: they can instantly ascertain the exact balance and status of any account simply by requesting the network for a specific branch of the tree, avoiding the need to adhere to Bitcoin’s multi-step 1-of-N “request all transaction outputs, then inquire about all transactions utilizing those outputs, and take the remainder” lightweight client paradigm.
Nevertheless, this state tree mechanism harbors a significant downside if executed in a simplistic manner: the intermediate nodes in the tree considerably inflate the required disk space for storing all the information. To understand why, examine this diagram here:

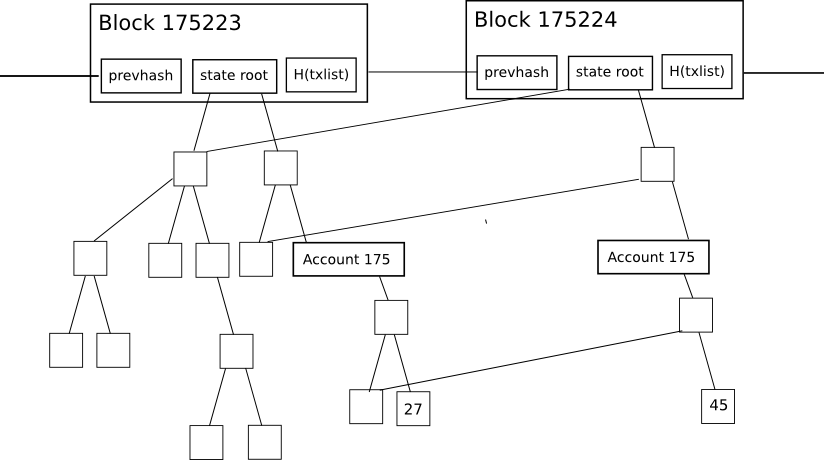
The alteration in the tree during each individual block is relatively minor, and the brilliance of the tree as a data structure lies in the fact that most data can be simply referenced multiple times without duplication. However, even so, for every modification made to the state, a logarithmically significant number of nodes (i.e., ~5 at 1000 nodes, ~10 at 1000000 nodes, ~15 at 1000000000 nodes) must be stored twice—one copy for the old tree and another for the new trie. Consequently, as a node processes each block, we can anticipate that the overall disk space utilization will be, in computer science terminology, approximately O(n*log(n)), where n represents the transaction load. In practical terms, the Ethereum blockchain is merely 1.3 gigabytes; however, the size of the database including all these additional nodes ranges from 10 to 40 gigabytes.
So, what options are available to us? One retrogressive solution is to simply move forward with implementing headers-first synchronization, effectively resetting new users’ hard disk usage back to zero, and enabling users to maintain low hard disk usage by re-synchronizing every month or two; however, this is not an aesthetically pleasing solution. The alternative is to enact state tree pruning: essentially, utilize reference counting to monitor when nodes in the tree (here using “node” in the computer science sense, referring to “data points situated within a graph or tree structure,” not “computers on the network”) drop out of the tree, and at that stage place them on “death row”: unless the node is somehow utilized again within the next X blocks (for example, X = 5000), following the passage of that number of blocks, the node should be permanently removed from the database. In essence, we retain the tree nodes that are part of the current state, as well as recent history, but we do not maintain history older than 5000 blocks.
X should be adjusted as low as feasible to save space, though setting X too low undermines durability: once this method is utilized, a node cannot revert back more than X blocks without effectively restarting synchronization entirely. Now, let’s examine how this approach can be thoroughly executed, considering all corner cases:
- While processing a block numbered N, keep track of all nodes (in the state, tree, and receipt trees) whose reference count falls to zero. Insert the hashes of these nodes into a “death row” database organized in a data structure that can subsequently be retrieved by block number (specifically, block number N + X), and mark the node database entry itself as eligible for deletion at block N + X.
- If a node on death row gets reinstated (a practical example of this is account A acquiring a specific balance/nonce/code/storage combination f, then switchingto a distinct value g, followed by account B obtaining state f while the node for f remains on death row), subsequently raise its reference count back to one. Should that node be removed again in a future block M (with M > N), then place it back on the future block’s death row for deletion at block M + X.
- Upon reaching the processing of block N + X, remember the list of hashes that you recorded during block N. Verify the node corresponding to each hash; if the node is still designated for deletion during that particular block (i.e., not reinstated, and crucially not reinstated and then re-designated for deletion later), remove it. Also, eliminate the list of hashes in the death row database.
- Occasionally, the new apex of a chain will not lie atop the previous apex, necessitating a block revert. In these instances, you will have to maintain in the database a journal of all alterations to reference counts (this is “journal” as in journaling file systems; basically, an ordered listing of the modifications made); when reverting a block, remove the death row list generated for that block, and reverse the changes made according to the journal (and dispose of the journal when finished).
- During block processing, eliminate the journal at block N – X; you are unable to revert more than X blocks anyway, rendering the journal unnecessary (and, if preserved, would indeed undermine the whole purpose of pruning).
Once this is completed, the database should solely hold state nodes related to the last X blocks, ensuring you maintain all essential information from those blocks but nothing beyond that. Furthermore, there are additional optimizations. Specifically, after X blocks, transaction and receipt trees ought to be entirely deleted, and even blocks might reasonably be removed as well – although there is a compelling argument for retaining some subset of “archive nodes” that preserve everything to assist the rest of the network in obtaining the data it requires.
So, how much savings could this provide us? As it turns out, quite significantly! Particularly, if we were to take the ultimate risk-taking approach and set X = 0 (i.e., lose all capability to manage even single-block forks, maintaining no history), then the database size would essentially match the size of the state: a figure which, as of now (this data was collected at block 670000) is approximately 40 megabytes – predominantly constituted of accounts like this one with storage slots filled to intentionally flood the network. At X = 100000, we would achieve practically the existing size of 10-40 gigabytes, as most of the increase occurred in the last hundred thousand blocks, and the additional space necessary for storing journals and death row lists would account for the remaining difference. For every value in between, we can anticipate the disk space increase to be linear (i.e., X = 10000 would bring us about ninety percent closer to near-zero).
Keep in mind that we might want to adopt a hybrid approach: retaining every block but not every state tree node; in this scenario, we would need to add approximately 1.4 gigabytes to store the block data. It’s crucial to highlight that the reason for the blockchain’s size is NOT rapid block times; currently, the block headers from the last three months comprise roughly 300 megabytes, while the remainder consists of transactions from the last month, thus at elevated levels of utilization we can expect transactions to continue to prevail. However, light clients will also need to prune block headers if they are to endure in low-memory conditions.
The aforementioned strategy has been executed in an early alpha stage in pyeth; it will be properly integrated into all clients in due course following the Frontier launch, as such storage expansion is merely a medium-term and not an immediate scalability issue.