



Merkle trees are an essential component of what drives blockchains. While it is theoretically feasible to construct a blockchain without Merkle trees by generating enormous block headers that encompass every transaction, such an approach presents significant scalability difficulties that arguably render the trustless use of blockchains out of reach for all but the most powerful computers over time. With the advent of Merkle trees, it becomes feasible to establish Ethereum nodes that function on various computers and laptops, regardless of size, smartphones, and even Internet of Things devices like those being developed by Slock.it. But how do these Merkle trees operate, and what advantages do they offer both now and looking ahead?
To begin, let’s cover the fundamentals. A Merkle tree, in its broadest definition, is a method of hashing a substantial quantity of “pieces” of data together, which relies on dividing the pieces into groups, with each group containing only a handful of pieces, followed by taking the hash of each group and repeating this process until only one hash remains: the root hash.
The most prevalent and basic variant of Merkle tree is the binary Merkle tree, where each group always comprises two neighboring pieces or hashes; it can be represented as follows:
So what advantages does this peculiar hashing algorithm offer? Why not simply link all the pieces into a single large piece and apply a standard hashing algorithm to it? The reason is that it enables a neat mechanism known as Merkle proofs:

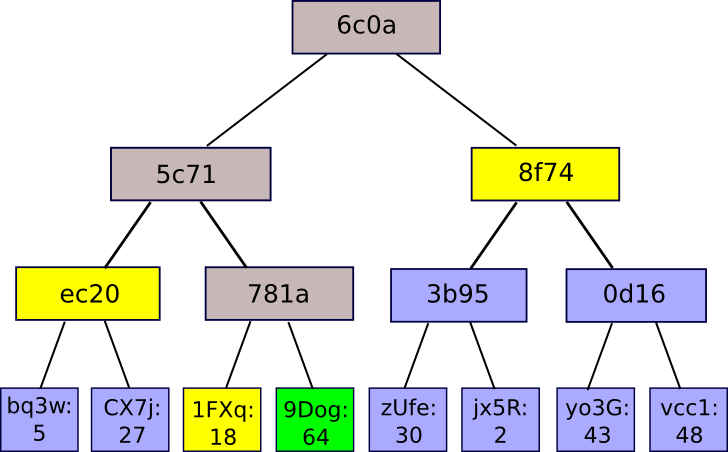
A Merkle proof comprises a piece, the root hash of the tree, and the “branch” consisting of all the hashes ascending from the piece to the root. Anyone examining the proof can confirm that the hashing, at least along that branch, is consistent from the base to the top of the tree, thereby verifying that the specified piece occupies that position in the tree. The application is straightforward: suppose there exists a large database, and the complete contents are stored in a Merkle tree where the root is publicly known and trustworthy (for example, it was digitally signed by a sufficient number of reliable parties, or it has considerable proof of work on it). A user wishing to perform a key-value lookup in the database (e.g., “provide me the object in position 85273”) can request a Merkle proof and, upon receiving the proof, confirm its accuracy, and thus ascertain that the data retrieved truly is at position 85273 in the database associated with that specific root. This facilitates a method for authenticating a small quantity of data, such as a hash, to also authenticate large databases that could potentially be unbounded in size.
Merkle Proofs in Bitcoin
The primary application of Merkle proofs was made in Bitcoin, as defined and developed by Satoshi Nakamoto in 2009. The Bitcoin blockchain employs Merkle proofs to store the transactions within each block:
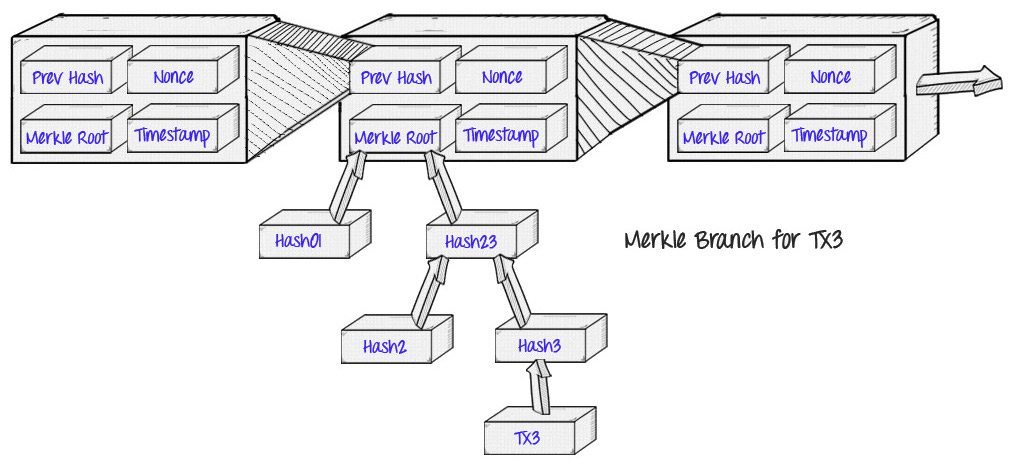

The value this provides is encapsulated in the concept that Satoshi termed “simplified payment verification”: rather than downloading every transaction and each block, a “light client” can download only the chain of block headers, which are 80-byte pieces of data for each block containing just five elements:
- A hash of the preceding header
- A timestamp
- A mining difficulty value
- A proof of work nonce
- A root hash for the Merkle tree comprising the transactions for that block.
If a light client wishes to ascertain the status of a transaction, it can simply request a Merkle proof demonstrating that a specific transaction is present in one of the Merkle trees whose root is included in a block header for the primary chain.
This takes us quite far, but Bitcoin-style light clients have their limitations. One notable restriction is that, while they can validate the inclusion of transactions, they cannot verify anything regarding the current state (e.g., digital asset holdings, name registrations, status of financial contracts, etc.). How many bitcoins are in your possession right now? A Bitcoin light client may employ a protocol involving inquiries to multiple nodes, trusting that at least one will alert you to any particular transaction spending from your accounts, which can be effective for that use case, but for other more complex situations, it falls short; the precise implications of a transaction may hinge on the consequences of several preceding transactions, which in turn depend on previous transactions, necessitating authentication of every single transaction in the complete chain. To circumvent this, Ethereum advances the Merkle tree concept to a higher level.
Merkle Proofs in Ethereum
Each block header in Ethereum incorporates not merely one Merkle tree but three trees catering to three different types of objects:
- Transactions
- Receipts (essentially, pieces of data illustrating the effects of each transaction)
- State
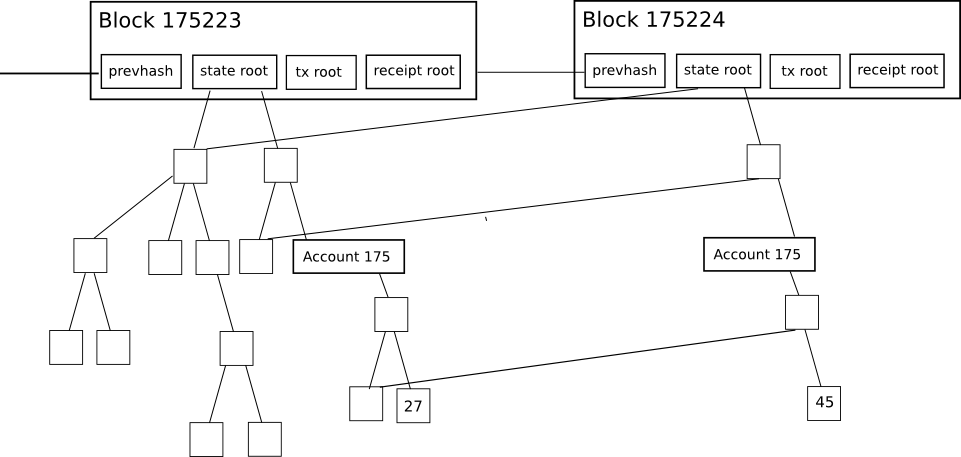

This permits a highly sophisticated light client protocol enabling light clients to easily generate and receive verifiable responses for many types of inquiries:
- Has this transaction been included in a specific block?
- Provide me all instances of an event of type X (e.g., a crowdfunding contract achieving its target) emitted by this address in the previous 30 days
- What is the current balance of my account?
- Does this account exist?
- Simulate executing this transaction on this contract. What would the output be?
The transaction tree manages the first inquiry; the third and fourth are addressed by the state tree, while the second is taken care of by the receipt tree. The first four are relatively simple to compute; the server merely locates the object and retrieves the Merkle branch (the sequence of hashes ascending from the object to the tree.root) and responds to the light client with the branch.
The fifth task is also managed by the state tree, but the manner in which it is calculated is more intricate. Here, we must generate what can be referred to as a Merkle state transition proof. In essence, it is a proof that posits, “if you execute transaction T on the state with root S, the resulting state will have the root S’, with log L and output O” (“output” is a concept in Ethereum since every transaction functions as a call; while it is not strictly necessary, it exists nonetheless).
To generate the proof, the server simulates a mock block locally, assigns the state to S, and acts as a light client while executing the transaction. That is, if applying the transaction requires the client to ascertain an account’s balance, the light client will perform a balance inquiry. If the light client needs to verify a specific item in a given contract’s storage, the light client conducts a query for that item, and so on. The server “answers” all of its queries accurately, while keeping track of all the data it returns. Subsequently, the server provides the client with the aggregated data from all these requests as proof. The client then follows the exact procedure, but utilizing the provided proof as its database; if its outcome matches what the server asserts, then the client endorses the proof.

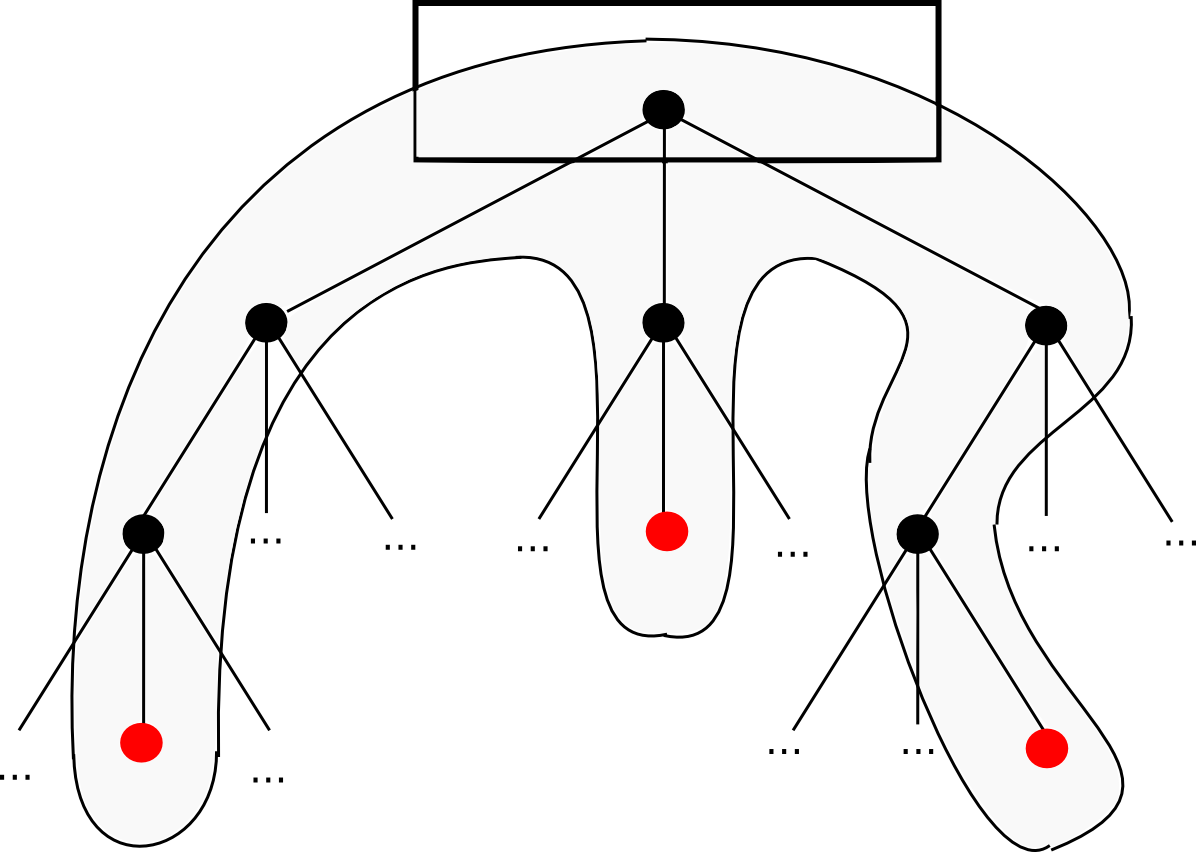
Patricia Trees
It was noted previously that the most straightforward form of Merkle tree is the binary Merkle tree; however, the types of trees utilized in Ethereum are more advanced – this is the “Merkle Patricia tree” that you often encounter in our documentation. This article will not delve into detailed specifications; that is better suited for this article and this one, though I will cover the fundamental reasoning.
Binary Merkle trees are highly effective data structures for authenticating data presented in a “list” format; essentially, a successive series of segments. For transaction trees, they are equally beneficial because the duration it takes to modify a tree post-creation is irrelevant, as the tree is established once and remains fixed thereafter.
In contrast, the situation for the state tree is more complicated. The state in Ethereum essentially represents a key-value map, where the keys are addresses and the values are account definitions, detailing the balance, nonce, code, and storage for each account (where the storage itself is a tree). For instance, the genesis state of the Morden testnet appears as follows:
{
"0000000000000000000000000000000000000001": {
"balance": "1"
},
"0000000000000000000000000000000000000002": {
"balance": "1"
},
"0000000000000000000000000000000000000003": {
"balance": "1"
},
"0000000000000000000000000000000000000004": {
"balance": "1"
},
"102e61f5d8f9bc71d0ad4a084df4e65e05ce0e1c": {
"balance": "1606938044258990275541962092341162602522202993782792835301376"
}
}
Unlike transaction history, however, the state demands frequent updates: the balance and nonce of accounts are subject to frequent changes, and furthermore, new accounts are continually added, while keys in storage are often inserted and deleted. Thus, we require a data structure that allows us to swiftly compute the new tree root following an insertion, update, or deletion operation, without the need to recompute the entire tree. There are also two highly sought-after secondary attributes:
- The depth of the tree is capped, even when faced with an attacker intentionally designing transactions to maximize the tree’s depth. Otherwise, an attacker could execute a denial of service attack by manipulating the tree to such an extent that every individual update becomes extremely sluggish.
- The root of the tree is determined solely by the data, not by the sequence of updates made. Applying updates in a different order, or even recalculating the tree from the ground up, should not alter the root.
The Patricia tree, in straightforward terms, is perhaps the nearest we can get to fulfilling all of these properties at once. The simplest way to describe its operation is that the key under which a value is stored is encoded into the “path” that must be traversed through the tree. Each node contains 16 offspring, so the path is determined by hex encoding: for instance, the key dog hex encoded is 6 4 6 15 6 7, thus you would initiate at the root, navigate down to the 6th child, then the fourth, and so on until you reach the end. In practice, there are several additional optimizations we can implement to enhance efficiency when the tree is sparse, but that is the foundational idea. The two articles previously cited above provide much greater detail on all of the characteristics.