



“`html
In the latest installment of The 1.x files, we provided a brief summary of the origins of the Eth 1.x research initiative, the stakes involved, and some potential remedies. We concluded with the idea of stateless ethereum, leaving a more thorough exploration of the stateless client for this article.
Stateless represents the fresh trajectory of Eth 1.x research, so we intend to conduct an in-depth investigation and acquire a clear understanding of the obstacles and opportunities anticipated in the future. For those seeking to delve even deeper, I will strive to provide links to more detailed resources whenever feasible.
The Condition of Stateless Ethereum
To understand our future direction, we must first grasp our current position regarding the notion of ‘state’. When we refer to ‘state’, we are referencing “a condition of affairs”.
The complete ‘state’ of Ethereum delineates the existing status of all accounts and balances, as well as the aggregated recollections of all smart contracts that are deployed and executing within the EVM. Each finalized block in the chain possesses a singular state, which is agreed upon by all participants within the network. That state is modified and refreshed with each new block added to the chain.
In the context of Eth 1.x research, it is not only crucial to know what state is, but also how it’s manifested in both the protocol (as delineated in the yellow paper) and in most client implementations (e.g., geth, parity, trinity, besu, etc.).
Utilize a Trie
The data arrangement utilized in Ethereum is termed a Merkle-Patricia Trie. Interesting tidbit: ‘Trie’ is derived from the term ‘retrieval’, yet most individuals pronounce it as ‘try’ to differentiate it from ‘tree’ in conversation. But I digress. What we need to comprehend about Merkle-Patricia Tries is as follows:
At one end of the trie, there reside all the specific pieces of data that define the state (value nodes). This could represent a specific account’s balance or a variable stored within a smart contract (like the total supply of an ERC-20 token). In the middle are branch nodes, which connect all values together through hashing. A branch node is an array containing the hashes of its child nodes, and each branch node is subsequently hashed and included in the array of its parent node. This sequential hashing ultimately leads to a single state root node at the opposite end of the trie.
In the simplified illustration above, we can observe each value as well as the path that indicates how to arrive at that value. For instance, to access V-2, we follow the path 1,3,3,4. Likewise, V-3 can be reached by following the path 3,2,3,3. Note that paths in this example are consistently 4 characters long, and there is frequently only a singular path to take in order to reach a value.
This architecture possesses the essential attribute of being deterministic and cryptographically verifiable: the sole method to generate a state root is by computing it from each individual piece of the state, and two identical states can be efficiently verified by comparing the root hash and the hashes that contributed to it (a Merkle proof). Conversely, there is no mechanism to create two distinct states with the same root hash, and any attempt to alter the state with varying values will result in an altered state root hash.
Ethereum enhances the trie structure by introducing a few new node types that improve efficiency: extension nodes and leaf nodes. These encode portions of the path into nodes so that the trie becomes more compact.
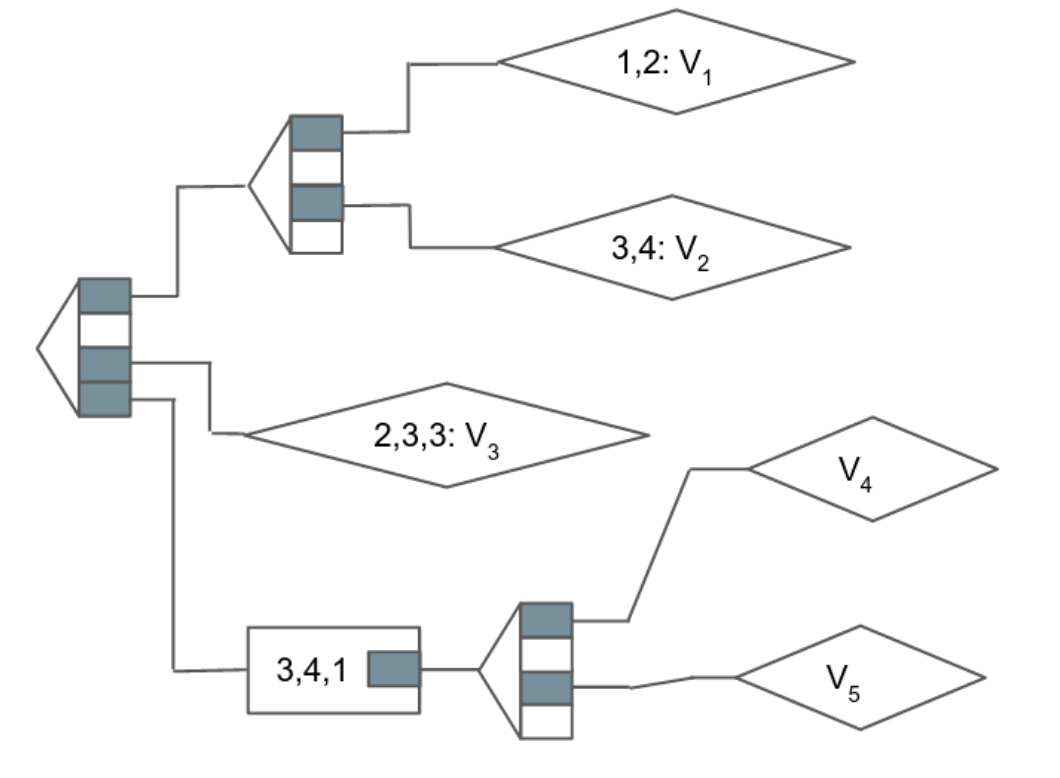

In this refined Merkle-Patricia trie structure, each node presents a choice between various subsequent nodes, a compressed segment of a path shared by subsequent nodes, or values (preceded by the rest of their path, if necessary). It’s the same data and the same configuration, but this trie requires just 9 nodes rather than 18. This appears more efficient, but in retrospect, it isn’t truly optimal. We’ll investigate the reasons in the upcoming section.
To reach a specific portion of state (like an account’s current Ether balance), one must start at the state root and navigate through the trie from node to node until the desired value is attained. At each node, characters in the path are utilized to determine the next node to traverse, akin to a divining rod, but for navigating hashed data arrangements.
In the ‘actual’ version implemented by Ethereum, paths are the hashes of an address 64 characters (256 bits) in length, and values are RLP-encoded data. Branch nodes are arrays consisting of 17 elements (sixteen corresponding to each possible hexadecimal character, and one for a value), while leaf nodes and extension nodes contain 2 elements (one partial path and either a value or the hash of the next child node). The Ethereum wiki is likely the most suitable place to read elaborately about this, or, if you wish to deeply explore the topic, this article offers an excellent (but regrettably deprecated) DIY trie exercise in Python to experiment with.
Embed it in a Database
At this juncture, we should remind ourselves that the trie structure is merely an abstract concept. It’s a method of compressing the entirety of Ethereum’s state into a single coherent structure. However, this structure then needs to be incorporated into the client’s code and stored on a disk (or several thousand of them distributed across the globe). This necessitates taking a multi-dimensional trie and fitting it into a conventional database that understands solely [key, value] pairs.
In most Ethereum clients (all
“`except turbo-geth), the Merkle-Patricia Trie is constructed by generating a separate [key, value] pair for each vertex, wherein the value represents the vertex itself, and the key denotes the hash of that vertex.
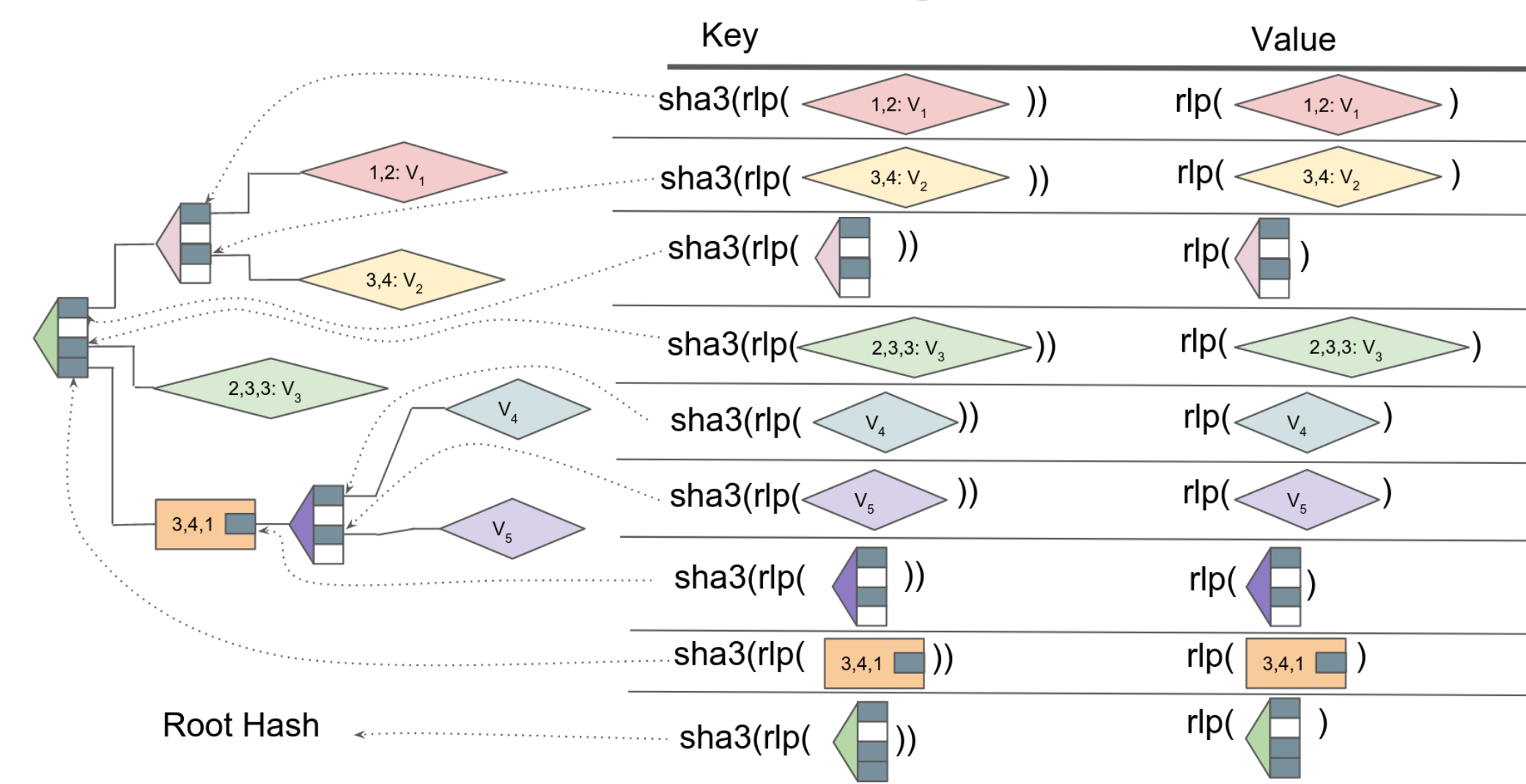

The method of navigating the trie is largely similar to the theoretical approach outlined previously. To retrieve an account balance, we commence with the root hash and search for its value in the database to obtain the initial branch node. By utilizing the first character of our hashed address, we identify the hash of the first vertex. This hash is looked up in the database, yielding our second vertex. Utilizing the subsequent character of the hashed address, we discover the hash of the third vertex. If fortune favors us, we might encounter an extension or leaf vertex during our traversal, potentially allowing us to avoid traversing all 64 nibbles. Eventually, we will reach the desired account and be able to extract its balance from the database.
Calculating the hash for each new block involves a similar process, but in reverse order: Beginning with all the edge vertices (accounts), the trie is assembled through progressive hashing, culminating in the creation of a new root hash which is then compared with the last consensus block in the chain.
This is where that aspect regarding the perceived efficiency of the state trie comes into consideration: reconstructing the entire trie is extremely resource-intensive on disk, and the modified Merkle-Patricia trie design employed by Ethereum is more protocol efficient at the expense of implementation efficiency. These additional vertex types, leaves and extensions, theoretically conserve memory required for storing the trie, but they complicate the algorithms that alter the state inside the conventional database. Naturally, a reasonably powerful computer can perform the task at impressive speed. However, sheer processing capability has its limitations.
Sync, baby, sync
Up to this point, we’ve focused our attention on what transpires within an individual computer executing an Ethereum implementation like geth. Nonetheless, Ethereum is a network, and the overarching aim of all of this is to maintain the same unified state consistent across thousands of computers globally and among different implementations of the protocol.
The continuously shifting tokens of #Defi, cryptokitty auctions, or cheeze wizard battles, along with regular ETH transactions, collectively contribute to a rapidly evolving state that Ethereum clients must maintain synchronization with, and it becomes increasingly challenging as Ethereum gains popularity and the state trie expands.
Turbo-geth is one implementation that addresses the core issue: It flattens the trie database and employs the path of a vertex (instead of its hash) as the [key, value] pair. This essentially renders the depth of the tree inconsequential for lookups, enabling various innovative features that can enhance performance and lessen the burden on disk when operating a full node.
The Ethereum state is substantial, and it evolves with each block. How substantial, and how much of an evolution? We can estimate the current state of Ethereum to be around 400 million vertices in the state trie. Among these, roughly 3,000 (and potentially up to 6,000) need to be added or adjusted every 15 seconds. Remaining synchronized with the Ethereum blockchain essentially entails perpetually constructing a new iteration of the state trie again and again.
This multi-phase procedure of state trie database operations is why Ethereum implementations demand significant disk I/O and memory, and why even a “fast sync” might take up to 6 hours to finalize, even on rapid connections. To operate a full node in Ethereum, a high-speed SSD (as opposed to an economical, dependable HDD) is a necessity, because processing state modifications is profoundly taxing on disk read/writes.
It is crucial to acknowledge that there exists a major and significant difference between creating a new node to sync and maintaining an existing node in sync — A distinction that, when we delve into stateless Ethereum, will potentially become indistinct (hopefully).
The simplest way to synchronize a node is via the “full sync” approach: Starting from the genesis block, a record of every transaction in each block is retrieved, and a state trie is constructed. With each subsequent block, the state trie is altered, adding and modifying vertices as the entire history of the blockchain is replayed. It takes a full week to download and execute a state change for every block from the outset, but it’s merely a matter of time before the transactions you require are awaiting inclusion into the next new block rather than being already cemented in an older one.
An alternative method, aptly named “fast-sync”, is swifter but more intricate: A new client can, instead of seeking transactions from the dawn of time, request state entries from a recent, credible ‘checkpoint’ block. This results in considerably less total data to download, yet it remains a substantial amount of information to process– sync is not currently constrained by bandwidth, but by disk performance.
A fast-syncing node essentially competes with the forefront of the chain. It must obtain all of the state at the ‘checkpoint’ before that state becomes outdated and ceases to be provided by full nodes (It can ‘pivot’ to a new checkpoint if such a scenario occurs). Once a fast-syncing node surmounts this challenge and fully updates its state with a checkpoint, it can transition to full sync — constructing and refreshing its own state copy from the included transactions in every block.
Can I get a block witness?
We can now begin to dissect the notion of stateless Ethereum. A primary objective is to make new nodes less arduous to initiate. Considering that only 0.1% of the state alters from block to block, it appears there ought to be a method to minimize all that excess ‘stuff’ that needs to be downloaded before switching to full sync.
However, this presents one of the challenges dictated by Ethereum’s cryptographically secure data structure: In a trie, a modification to even a single value leads to a completely different root hash. That’s a feature, not a flaw! It ensures everyone is confident that they are aligned with one another (at the same state) across the network.
To obtain a shortcut, we require a new piece of information about state: a block witness.
Imagine that only a single value in this trie has been modified recently (marked in green):
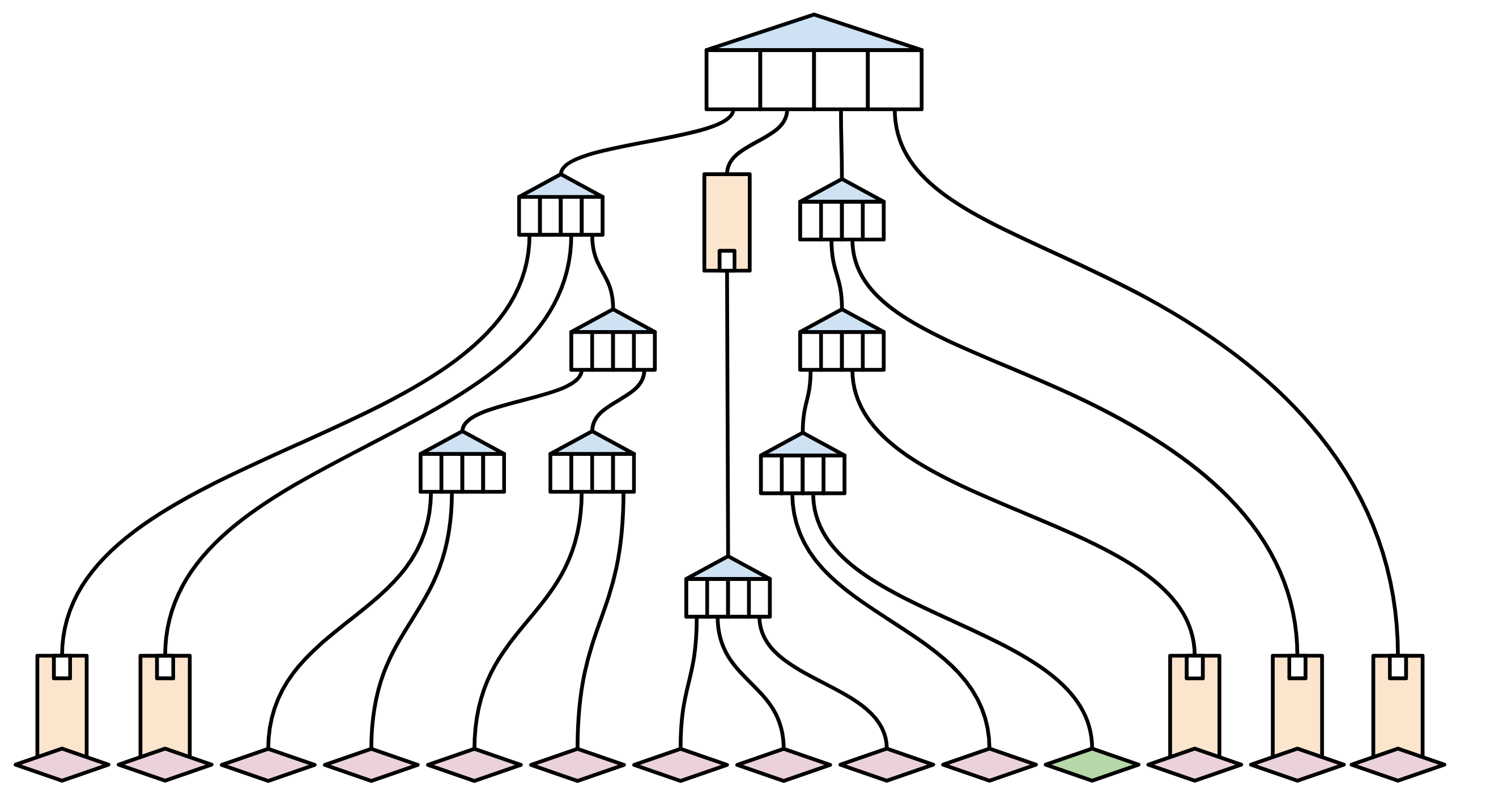

A complete node synchronizing the state (including this transaction) will proceed in the traditional manner: By aggregating all the elements of state and hashing them collectively to produce a new root hash. This allows them to easily confirm that their state aligns with that of others (as they possess the identical hash, along with the same transaction history).
But what about an individual who has just tuned in? What is the least amount of information that a new node needs in order to validate that — at least for the duration it has been observing — its perceptions are in harmony with everyone else’s?
A new, uninformed node will require experienced full nodes to furnish evidence that the recognized transaction fits into the entirety of what they’ve encountered regarding the state.
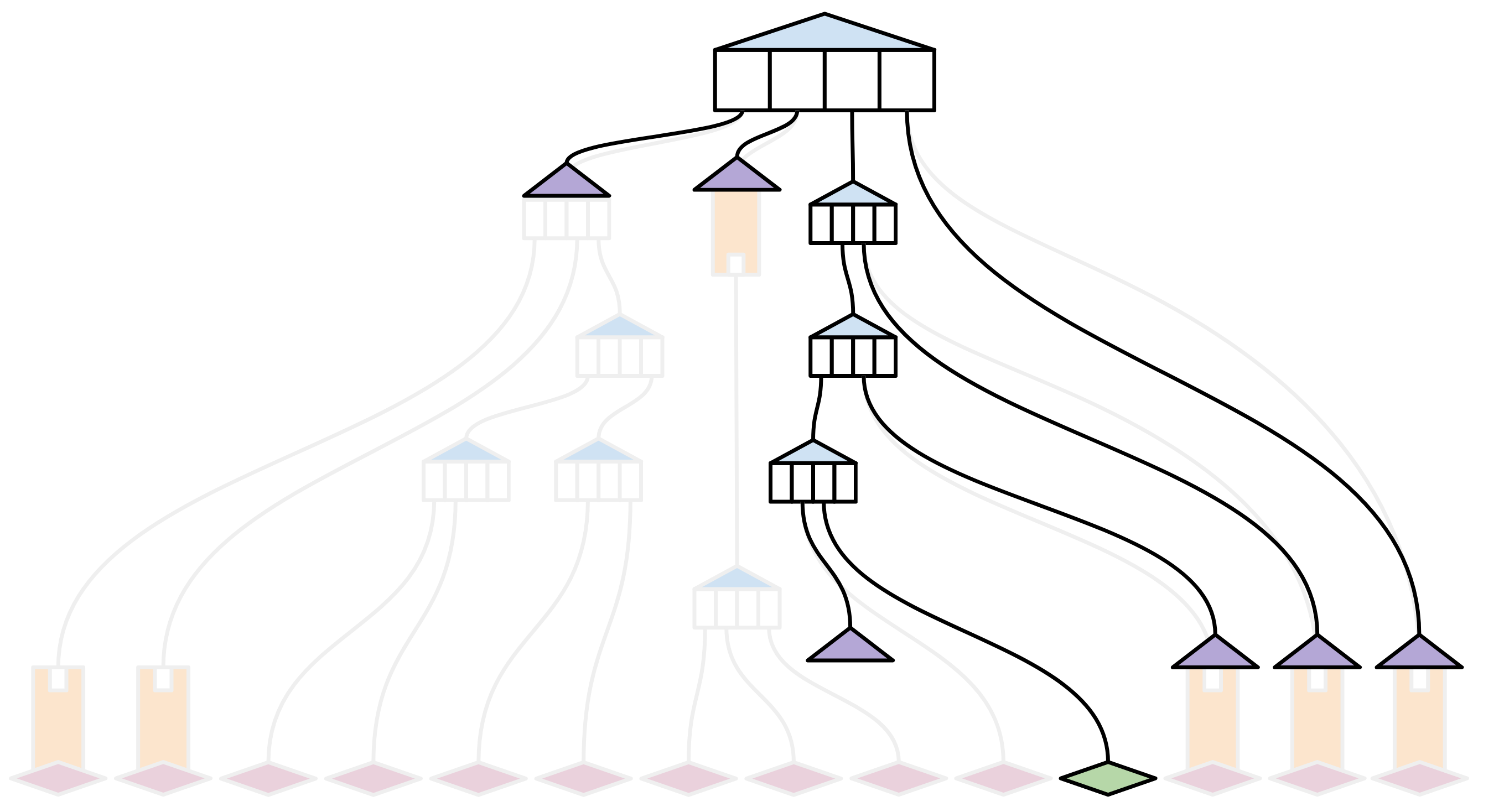

In very abstract terms, a block witness proof supplies all the absent hashes in a state trie, along with some ‘structural’ data indicating where within the trie those hashes belong. This enables an ‘uninformed’ node to integrate the new transaction into its state, and to calculate the new root hash locally — without necessitating a complete download of the entire state trie.
This encapsulates the core concept behind beam sync. Rather than waiting to collect each node in the checkpoint trie, beam sync starts observing and attempting to execute transactions as they occur, requesting a witness with each block from a full node for any information it lacks. As more of the state is ‘interacted with’ by newer transactions, the client can increasingly depend on its own copy of the state, which (in beam sync) will gradually compile until it eventually transitions to full sync.
Statelessness is a spectrum
With the advent of a block witness, the idea of ‘fully stateless’ begins to take on a clearer definition. Simultaneously, it’s where we encounter open queries and issues with no clear-cut solution.
In contrast to beam sync, a truly stateless client would never retain a copy of the state; it would merely acquire the latest transactions along with the witness, possessing everything it needs to execute the forthcoming block.
You might observe that if the entire network were stateless, this scenario could potentially persist indefinitely– witnesses for new blocks can be generated from the previous block. It would be witnesses all the way down! At least, down to the last mutually recognized ‘state of affairs’, and the first witness generated from that state. Such a drastic, significant shift in Ethereum is unlikely to gain widespread endorsement.
A less radical approach is to accommodate various levels of ‘statefulness’, creating a network in which some nodes maintain a full copy of the state and can provide fresh witnesses to everyone else.
-
Full-state nodes would function as before, but would also compute a witness and either attach it to a new block, or propagate it through a secondary network sub-protocol.
-
Partial-state nodes might maintain a full state for just a limited number of blocks, or perhaps only ‘observe’ the segment of state that they are interested in, retrieving the remaining necessary data to verify blocks from witnesses. This would greatly assist developers creating infrastructure for dapps.
-
Zero-state nodes, defined as wanting to keep their clients as lightweight as possible, could depend entirely on witnesses to verify new blocks.
Implementing this scheme might involve mechanisms similar to bittorrent-style chunking and swarming behavior, wherein witness segments are disseminated based on their necessity and optimal connections to other nodes with (complementary) partial state. Alternatively, it may include developing an alternative implementation of the state trie that is more conducive to witness generation. This represents avenues for exploration and prototyping!
For a far more comprehensive analysis of the trade-offs between stateful and stateless nodes, refer to Alexey Akhunov’s The shades of statefulness.
A pivotal aspect of the semi-stateless method is that these modifications do not automatically imply substantial, hard-forking changes. Through small, testable, and incremental enhancements, it is feasible to develop the stateless component of Ethereum into a supportive sub-protocol, or as a series of uncontroversial EIPs rather than a substantial ‘leap-of-faith’ upgrade.
The road(map) ahead
The predominant consideration in the research space is witness size. Standard blocks consist of a header, alongside a list of transactions, and typically measure approximately 100 kB. This size is sufficiently small to ensure that the propagation of blocks remains rapid relative to network latency and the 15-second block time.
Witnesses, however, must encapsulate the hashes of nodes both at the edges and deep within the state trie. Consequently, they are significantly larger: initial estimates suggest they could be around 1 MB. Therefore, syncing a witness is considerably slower in comparison to network latency and block time, which could pose an issue.
This dilemma resembles the disparity between downloading a film or streaming it: If the network is too sluggish to maintain the stream, downloading the entire film becomes the sole viable option. Conversely, if the network is significantly faster, streaming the film presents no issues. In between, more data is essential to make a decision. Those with subpar ISPs will appreciate the challenge of attempting to stream a Friday night movie over a network that might be inadequate for the job.
This is primarily where we delve into the specific challenges that the Eth 1x group is addressing. Currently, not enough is understood about the anticipated witness network to definitively ascertain its proper or optimal functioning, but the intricacies lie in the details (and the data).
One line of exploration involves considering methods to compress and diminish the size of witnesses by altering the structure of the trie itself (such as a binary trie), aiming to enhance efficiency at the implementation level. Another strategy is to prototype the network primitives (bittorrent-style swarming) that facilitate the effective circulation of witnesses across various nodes in the network. Both approaches would greatly benefit from a formalized witness specification — which is still not in existence.
All these directions (and beyond) are being consolidated into a more structured roadmap, which will be refined and made public in the upcoming weeks. The topics highlighted on the roadmap will serve as subjects for future in-depth explorations.
If you’ve reached this point, you should have a solid understanding of what “Stateless Ethereum” encompasses, along with some context surrounding the emerging Eth1x R&D.
As always, should you have inquiries regarding Eth1x initiatives, suggestions for topics, or wish to contribute, feel free to introduce yourself on ethresear.ch or contact @gichiba and/or @JHancock on Twitter.
Special acknowledgment to Alexey Akhunov for providing technical insights and some of the trie illustrations.
Wishing you a prosperous new year, and a successful Muir Glacier hardfork!