



A remark regarding the Stateless Ethereum project:
Research efforts have (understandably) diminished in the latter part of 2020 as all participants have adapted to life on the unusual timeline. Nevertheless, as the environment gradually approaches Serenity and the Eth1/Eth2 integration, Stateless Ethereum initiatives will gain more significance and influence. Anticipate a more comprehensive year-end review of Stateless Ethereum in the upcoming weeks.
Let’s revisit the recap once more: The primary aim of Stateless Ethereum is to eliminate the necessity for an Ethereum node to maintain a complete copy of the updated state trie at all times, and to allow state modifications to depend on a (much smaller) piece of information that verifies a specific transaction is enacting a valid change. Achieving this addresses a significant challenge for Ethereum; a challenge that has thus far only been deferred by enhanced client software: State expansion.
The Merkle proof required for Stateless Ethereum is termed a ‘witness’, and it validates a state transition by offering all the constant intermediate hashes necessary to attain a new valid state root. Witnesses are theoretically much smaller than the complete Ethereum state (which requires 6 hours at most to sync), yet they remain considerably larger than a block (which must disseminate throughout the entire network in just a few seconds). Therefore, minimizing the size of witnesses is crucial for establishing Stateless Ethereum’s minimum viable utility.
Much like the Ethereum state itself, a substantial portion of the additional (digital) mass in witnesses originates from smart contract code. If a transaction invokes a specific contract, the witness will by default have to encompass the contract bytecode in full within the witness. Code Merkelization is a general method aimed at alleviating the load of smart contract code within witnesses, enabling contract calls to only include the segments of code that they ‘interact’ with to validate their correctness. With this approach alone, we may observe a considerable decrease in witness size, but there are numerous factors to evaluate when dividing smart contract code into manageable byte-sized portions.
What constitutes Bytecode?
There are certain trade-offs to consider when fragmenting contract bytecode. The inquiry we will ultimately need to make is “what size will the code segments be?” – but for the moment, let’s examine some actual bytecode in a very elementary smart contract to grasp what it entails:
pragma solidity >=0.4.22 0.7.0; contract Storage { uint256 number; function store(uint256 num) public { number = num; } function retrieve() public view returns (uint256){ return number; } }
When this basic storage contract is compiled, it converts into the machine instructions designed to operate ‘within’ the EVM. Here, you can observe the same basic storage contract depicted above, but compiled into individual EVM operation codes (opcodes):
PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH1 0xF JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST POP PUSH1 0x4 CALLDATASIZE LT PUSH1 0x32 JUMPI PUSH1 0x0 CALLDATALOAD PUSH1 0xE0 SHR DUP1 PUSH4 0x2E64CEC1 EQ PUSH1 0x37 JUMPI DUP1 PUSH4 0x6057361D EQ PUSH1 0x53 JUMPI JUMPDEST PUSH1 0x0 DUP1 REVERT JUMPDEST PUSH1 0x3D PUSH1 0x7E JUMP```asm JUMPDEST PUSH1 0x40 MLOAD DUP1 DUP3 DUP2 MSTORE PUSH1 0x20 ADD SWAP2 POP POP PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 RETURN JUMPDEST PUSH1 0x7C PUSH1 0x4 DUP1 CALLDATASIZE SUB PUSH1 0x20 DUP2 LT ISZERO PUSH1 0x67 JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST DUP2 ADD SWAP1 DUP1 DUP1 CALLDATALOAD SWAP1 PUSH1 0x20 ADD SWAP1 SWAP3 SWAP2 SWAP1 POP POP POP PUSH1 0x87 JUMP JUMPDEST STOP JUMPDEST PUSH1 0x0 DUP1 SLOAD SWAP1 POP SWAP1 JUMP JUMPDEST DUP1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP POP JUMP INVALID LOG2 PUSH5 0x6970667358 0x22 SLT KECCAK256 DUP13 PUSH7 0x1368BFFE1FF61A 0x29 0x4C CALLER 0x1F 0x5C DUP8 PUSH18 0xA3F10C9539C716CF2DF6E04FC192E3906473 PUSH16 0x6C634300060600330000000000000000
As stated in a prior article, these opcode directives comprise the fundamental functions of the EVM’s stack framework. They outline the basic storage contract, along with all the operations it encompasses. This contract can be located as one of the sample solidity contracts in the Remix IDE (It is essential to note that the machine code presented above represents the storage.sol after it has already been deployed, rather than the output from the Solidity compiler, which includes additional ‘bootstrapping’ opcodes). If you allow your gaze to blur and envision a tangible stack machine steadily processing one opcode card at a time, the rapid motion of the stack almost allows you to perceive the shapes of functions arranged within the Solidity contract.
Each time the contract receives a message call, this code is executed within every Ethereum node verifying new blocks in the network. To issue a legitimate transaction on Ethereum today, one must possess a complete copy of the contract’s bytecode, as running that code from start to finish is the sole method to achieve the (deterministic) output state and the corresponding hash.
Stateless Ethereum, keep in mind, seeks to modify this requirement. Suppose all you intend to do is invoke the function retrieve() and nothing else. The logic explaining that function is merely a fraction of the entire contract, and in this scenario the EVM fundamentally requires only two of the core blocks of opcode instructions to return the desired result:
PUSH1 0x0 DUP1 SLOAD SWAP1 POP SWAP1 JUMP, JUMPDEST PUSH1 0x40 MLOAD DUP1 DUP3 DUP2 MSTORE PUSH1 0x20 ADD SWAP2 POP POP PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 RETURN
Within the Stateless framework, similarly to how a witness supplies the absent hashes of untouched state, a witness ought to furnish the lacking hashes for unexecuted segments of machine code, so that a stateless client only demands the portion of the contract it is executing.
The Code’s Witness
Smart contracts in Ethereum reside in the same location as externally-owned accounts: as leaf nodes within the vast single-rooted state trie. Contracts, in various respects, are no different from the externally-owned accounts that individuals utilize. They possess an address, can initiate transactions, and maintain a balance of Ether and any other token. However, contract accounts are unique because they are required to contain their own program logic (code), or a hash of it. Another corresponding Merkle-Patricia Trie, known as the storageTrie, preserves any variables or persistent state that an operational contract employs to function during execution.
This witness visualization offers a valuable perspective on how vital code merklization may be in minimizing the size of witnesses. Observe that substantial block of colored squares and how its volume exceeds all the other elements in the trie? That constitutes an entire serving of smart contract bytecode.
Adjacent to it and somewhat lower are the components of persistent state within the storageTrie, such as ERC20 balance mappings or ERC721 digital item ownership records. As this instance is a witness rather than a complete state snapshot, those too are chiefly composed of intermediate hashes, and solely include the alterations a stateless client would need to validate the next block.
Code merkleization aims to dissect that immense block of code and replace the field codeHash within an Ethereum account with the root of another Merkle Trie, aptly designated the codeTrie.
Worth its Weight in Hashes
Let’s examine an illustration from this Ethereum Engineering Group video, which evaluates several approaches to code chunking via an ERC20 token contract. Since a number of the tokens you are familiar with conform to the ERC-20 standard, this presents a suitable real-world context to comprehend code merkleization.
Due to bytecode being lengthy and unwieldy, let’s implement a straightforward shorthand by substituting four bytes of code (8 hexadecimal characters) with either a . or X character, with the latter denoting bytecode necessary for the execution of a particular function (in this scenario, the ERC20.transfer() function is utilized consistently).
In the ERC20 example, invoking the transfer() function utilizes just under half of the entire smart contract:
```XXX.XXXXXXXXXXXXXXXXXX........................................ ........................................ ........................XXX...............................XX.. ............................................XXXXXXXXXX XXXXXXXXXXXXXXXXXX...............XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.................................... ...............................................XXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXX....................```html .................................... ....
If we aim to divide that code into segments of 64 bytes, merely 19 out of the 41 segments would be necessary to perform a stateless transfer() operation, with the remaining data sourced from a witness.
|XXX.XXXXXXXXXXXX|XXXXXX..........|................|................ |................|.....XXXXXX.....|................|................ |............XXXX|XXXXXXXX........|...... ``````html ..........|................ |................|........XXX.....|................|............XX.. |................|................|......XXXXXXXXXX |XXXXXXXXXXXXXXXX|XX..............|.XXXXXXXXXXXXXXX|XXXXXXXXXXXXXXXX |XXXXXXXXXXXXXXXX|XXXXXXXXXXXXXX..|................|.............. ``````html .. |................|................|.......XXXXXXXXX |XXXXXXXXXXXXXXXX|XXXXXXXXXXXXX...|................|................ |....
Contrast this with 31 out of 81 segments in a 32 byte segmentation method:
|XXX.XXXX|XXXXXXXX|XXXXXX..|...... ```..|........|........|........|........ |........|........|.....XXX|XXX.....|........|........|........|........ |........|........|........|........|XXX.....|..```html ......|........|........|........|........|........|........|........|......XX|XXXXXXXX |XXXXXXXX|XXXXXXXX|XX......|........|.XXXXXXX|XXXXXXXX|XXXXXXXX|XXXXXXXX |XXXXXXXX|XXXXXXXX|XXXXXXXX|XXXXXX..|........|........|........ |........|........|........| ```........|........|........|.......X|XXXXXXXX |XXXXXXXX|XXXXXXXX|XXXXXXXX|XXXXX...|........|........|........|.......X |XXXXXXXX|........|........|........|........|........ |....
At first glance, it appears that smaller segments are more effective than larger ones, since the largely-empty segments show up less frequently. Yet, it is crucial to keep in mind that unutilized code also incurs a cost: each non-executed code segment gets substituted by a hash of fixed dimensions. When using smaller code segments, the total number of hashes for unused code rises, and those hashes can range from 8 bytes to as large as 32 bytes. You might be tempted to think, “Hold up! If the hash of code segments is consistently sized at 32 bytes, how does substituting 32 bytes of code with 32 bytes of hash make a difference!?”
Remember that the contract code is merkleized, implying that all hashes are interconnected within the codeTrie — the root hash of which is necessary for validating a block. In this arrangement, any sequential unexecuted segments only call for a single hash, regardless of their quantity. In essence, one hash can represent a potentially extensive limb filled with sequential segment hashes on the merkleized code trie, as long as none of them are needed for code execution.
We Must Gather Additional Data
The conclusion we are arriving at feels somewhat anticlimactic: There is no absolutely ‘optimal’ approach for code merkleization. Design choices such as fixing the dimensions of code segments and hashes hinge on data gathered regarding the ‘real world’. Each smart contract will merkleize in its own unique manner, thus researchers hold the responsibility to select the format that yields the highest efficiency improvements for observed activity on the mainnet. What does this imply, specifically?
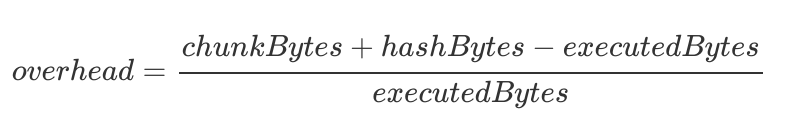

One aspect that may indicate the efficiency of a code merkleization scheme is Merkleization overhead, which addresses the inquiry, “how much supplementary information aside from executed code is being incorporated in this witness?”
Already, we have some encouraging results, obtained through a specialized instrument created by Horacio Mijail from Consensys’ TeamX research group, demonstrating overheads as minor as 25% — quite impressive!
In summary, the data indicates that, generally, smaller segment sizes are more effective than larger sizes, particularly when smaller hashes (8 bytes) are utilized. However, these initial statistics are by no means exhaustive, as they reflect merely about 100 recent blocks. If you happen to be reading this and are keen on supporting the Stateless Ethereum endeavor by gathering more robust data related to code merkleization, please introduce yourself on the ethresear.ch forums, or join the #code-merkleization channel on the Eth1x/2 research discord!
And as always, for inquiries, suggestions, or requests related to “The 1.X Files” and Stateless Ethereum, feel free to DM or @gichiba on twitter.