


T'was the eve prior to genesis, when all was ready, geth was in sync, my beacon node connected. Firewalls set, VLANs a plenty, hours of readiness meant nothing was empty.
Then all of a sudden, everything went awry, the SSD in my setup decided to die. My configurations disappeared, chain data became past, nothing to do but rely on next-day delivery.
I found myself crafting backups and alternatives. Complex systems consumed my dreams. Realizing further, I grasped: fearing these types of failures was quite unwise.
Events
The beacon chain possesses multiple mechanisms to motivate validator actions, all of which rely on the ongoing state of the network, making it crucial to evaluate these failure scenarios in the larger context of how other validators may falter when determining which methods are, and aren’t, beneficial for securing your node(s).
As a participating validator, your balance either rises or falls; it never stays stagnant*. Hence, a quite logical strategy to maximize your earnings is to reduce your risks. The beacon chain can diminish your balance in three ways:
- Penalties are imposed when your validator neglects one of its responsibilities (e.g., due to being offline)
- Inactivity Leaks are applied to validators who miss their responsibilities while the network fails to reach finality (i.e., when your validator being offline is noticeably linked to other validators being offline)
- Slashings are enforced on validators who create blocks or attestations that are conflicting and could potentially facilitate an attack
* Typically, a validator’s balance might remain constant, but for any specific duty, they are either rewarded or penalized.
Correlation
The influence of a single validator being offline or engaging in slashable actions is minimal regarding the overall wellness of the beacon chain. It is consequently not subjected to severe penalties. Conversely, if numerous validators are offline, the balance of those offline validators can decrease significantly quicker.
Likewise, if many validators commit slashable acts simultaneously, from the viewpoint of the beacon chain, this is indistinct from an assault. Therefore, it is treated accordingly, and 100% of the stakes of the culpable validators are forfeited.
Due to these “anti-correlation” incentives, validators should be more concerned about failures that could impact others at the same time rather than isolated, individual issues.
Causes and their probability.
Thus, let’s analyze some failure scenarios and review them through the framework of how many others would be impacted simultaneously, and how severely your validators would be penalized.
I disagree with @econoar here that these are worst-case situations. These represent more moderate-level challenges. Home UPS and Dual WAN addressing failures are not correlated with other users and should be placed much lower on your list of concerns.
🌍 Internet/power failure
If you are validating from home, it’s quite probable that you’ll encounter one of these failures at some time in the future. Residential internet and power connections lack guaranteed uptime. However, when the internet does go down, or your power is out, the outage is typically confined to your locality and usually only lasts for a few hours.
Unless you experience extremely unreliable internet/power, investing in fall-over connections might not be worthwhile. You will incur some hours of penalties, but as the remainder of the networkis operating as expected, your penalties will be approximately equal to the rewards you would have received during the same timeframe. In other terms, a k hour-long outage will bring your validator’s balance back to around where it stood k hours prior to the outage, and within k more hours, your validator’s balance will indeed return to its pre-outage figure.
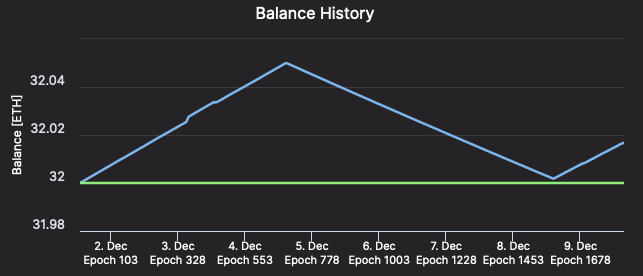

[Validator #12661 recovering ETH as swiftly as it was lost – Beaconcha.in
🛠 Equipment malfunction
Similar to internet disruptions, hardware malfunctions occur unexpectedly, and when they do, your node might be inactive for several days. It is important to evaluate the anticipated rewards over the validator’s lifespan against the expenditure of backup hardware. Is the expected cost of failure (the offline penalties multiplied by the likelihood of occurrence) higher than the price of the backup hardware?
Personally, the risk of malfunction is sufficiently low, and the cost for complete redundant hardware is high enough that it is likely not worthwhile. However, I am not a whale 🐳; as with any failure scenario, you must assess how this pertains to your specific circumstances.
☁️ Cloud service interruption
To completely sidestep the hazards of hardware or internet failures, you may opt for a cloud provider. Yet, choosing a cloud provider introduces the risk of correlated failures. The critical question becomes, how many other validators are utilizing the same cloud provider as you?
A week prior to the genesis, Amazon AWS experienced a significant outage that impacted a vast segment of the internet. Should a similar event occur now, enough validators would become inactive simultaneously that the inactivity penalties would activate.
Even more critically, if a cloud provider were to duplicate the virtual machine operating your node and inadvertently leave both the old and new node active at the same time, you could face slashing (the penalties could be particularly severe if this unintended duplication influenced many other nodes as well).
If you’re determined to depend on a cloud provider, contemplate switching to a smaller provider. This could potentially save you a considerable amount of ETH.
🥩 Staking Services
There are numerous staking services on the mainnet currently, each exhibiting varying degrees of decentralization, yet they all carry an elevated risk of correlated failures if you entrust them with your ETH. These services serve as vital elements of the eth2 ecosystem, particularly for those possessing less than 32 ETH or lacking the technical expertise to stake, but they are created by humans and are thus fallible.
Should staking pools expand to sizes similar to eth1 mining pools, it is plausible that a bug could trigger widespread slashing or inactivity penalties for their participants.
🔗 Infura Disruption
Recently, Infura was down for 6 hours, causing interruptions throughout the Ethereum ecosystem; it is evident how this could lead to correlated failures for eth2 validators.
Additionally, third-party eth1 API providers inevitably implement rate limiting on their service: this has previously resulted in validators being unable to produce valid blocks (during the Medalla testnet).
The best course of action is to operate your own eth1 node: this will eliminate rate limitations, reduce the likelihood of correlated failures, and enhance the overall decentralization of the network.
Eth2 clients have also begun incorporating the ability to specify multiple eth1 nodes. This simplifies the process of switching to a backup endpoint in the event that your primary one fails (Lighthouse: –eth1-endpoints, Prysm: PR#8062, Nimbus & Teku are expected to include support in the near future).
I strongly advise incorporating backup API options as economical or free insurance (EthereumNodes.com lists the free and paid API endpoints along with their current status). This is beneficial whether you manage your own eth1 node or not.
🦏 Failure of a specific eth2 client
In spite of all the code reviews, audits, and exceptional work, every eth2 client harbors bugs that could emerge at any time. Many of these issues are minor and likely to be detected before they escalate into significant problems in operation, but there remains a possibility that the client you select might go offline or lead to slashing. If this occurs, you would prefer not to be using a client that represents more than 1/3 of the nodes in the network.
You need to find a balance between what you believe to be the best client versus how widely adopted that client is. It could be wise to delve into the documentation of an alternative client so that, in the event of a node issue, you’re prepared for the process of installing and setting up another client.
If you have a significant amount of ETH at risk, it would likely be beneficial to operate several clients, each managing some of your ETH to avoid concentrating all your resources in a single entity. Otherwise, Vouch presents an intriguing option for multi-node staking infrastructure, and Secret Shared Validators are advancing rapidly.
🦢 Unexpected Eventsswans
There are indeed numerous improbable, unforeseen, yet perilous situations that will consistently pose a risk. Situations that reside beyond the evident choices regarding your staking arrangement. Instances such as Spectre and Meltdown at the hardware level, or kernel vulnerabilities like BleedingTooth illustrate some of the risks that are present throughout the complete hardware stack. By nature, it is impossible to fully anticipate and avert these issues; typically, you must respond post-incident.
What to be concerned about
Ultimately, this boils down to assessing the expected value E(X) of a potential failure: how probable it is for an event to occur, and the repercussions should it happen. It is crucial to take these failures into account in relation to the rest of the eth2 network as the correlation significantly impacts the penalties involved. Evaluating the anticipated cost of a failure against the expense of mitigating it will provide you with the logical conclusion as to whether it is worthwhile to address it proactively.


No one is aware of all the ways a node can fail, nor the probability of each type of failure, but by formulating individual assessments of the likelihood for each failure type and alleviating the most significant risks, the “wisdom of the crowd” will triumph, and on average, the network as a whole will arrive at a sensible estimate. Additionally, due to the various risks faced by each validator, as well as the differing evaluations of those risks, the failures you did not foresee will be identified by others, thus diminishing the degree of correlation. Yay decentralisation!
📕 DON’T FREAK OUT
In conclusion, if anything occurs with your node, do not freak out! Even during inactivity leaks, penalties are minimal in short durations. Take a few moments to contemplate what transpired and why. Then devise a plan of action to resolve the issue. Then inhale deeply before proceeding. An additional 5 minutes of penalties is preferable to being penalized because you acted hastily without thinking.
Most importantly: 🚨 Never operate 2 nodes with identical validator keys! 🚨
Thanks to Danny Ryan, Joseph Schweitzer, and Sacha Yves Saint-Leger for their review
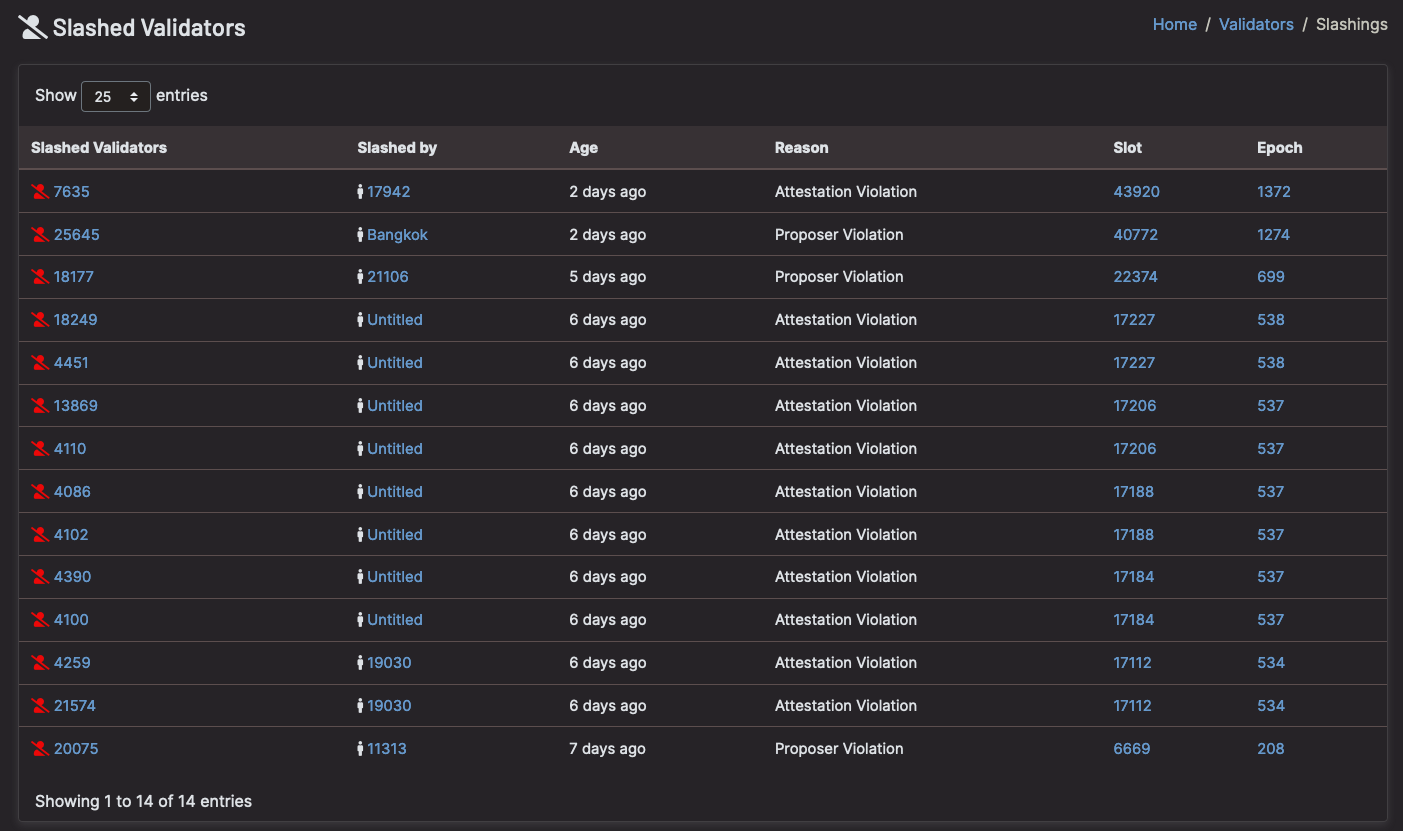

[Slashings due to validators operating >1 node – Beaconcha.in]